

大规模分布式存储系统_配置底层存储系统

1. 引言
在当前信息化和数字化时代,数据已经成为企业的核心资产之一,随着数据量的急剧增加,传统的单机存储系统已经无法满足大数据的存储需求,大规模分布式存储系统(如Hadoop HDFS)应运而生,为海量数据的存储和管理提供了有效的解决方案,本文将详细介绍如何配置底层存储系统以支持大规模分布式存储。
2. 设计原理与架构
2.1 设计原理
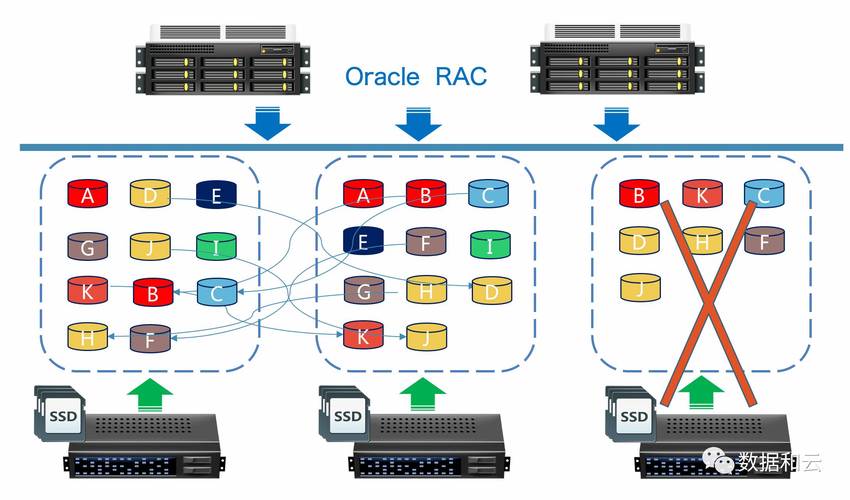
大规模分布式存储系统的设计原理基于“分而治之”的策略,即将大文件分割成固定大小的数据块(Block),分布在多个计算节点上进行并行处理和冗余存储,这种设计能够有效处理PB级别的数据存储,并支持高吞吐量的数据访问。
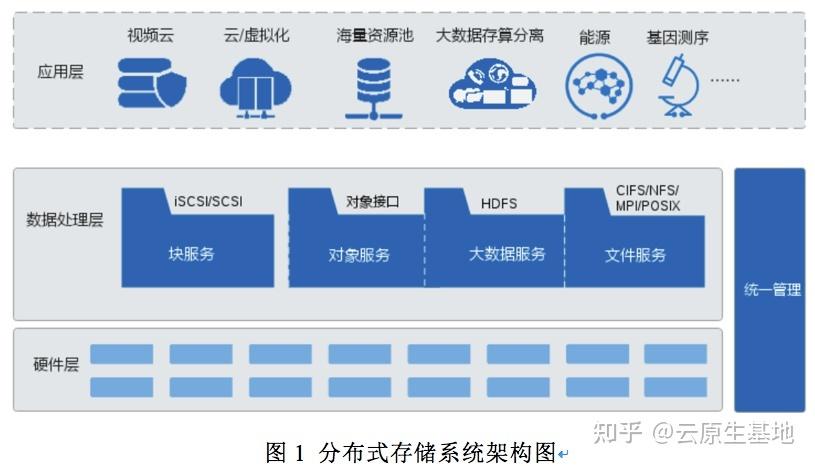
2.2 系统架构
NameNode:负责维护文件系统的命名空间、管理文件系统树及所有文件和目录的元数据信息。
DataNode:负责处理客户端的读写请求,实际存储数据,并定期向NameNode发送心跳信号和块报告。
Secondary NameNode:定期合并NameNode的编辑日志和文件系统镜像,减少NameNode启动时间,并在故障时用于恢复。
Client:提供API以便应用程序读取、写入和管理分布式文件系统中的文件。
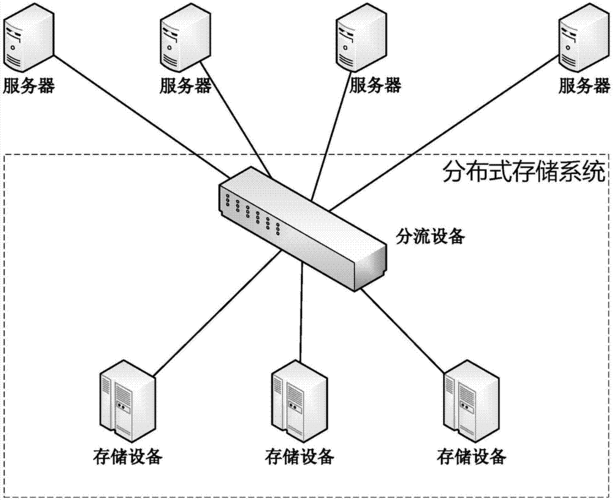
3. 关键技术
3.1 数据块(Block)
分割大文件:将文件分割成固定大小的数据块(默认128MB),每个数据块分布在多个DataNode上实现分布式存储。
副本机制:每个数据块默认有三个副本,分布在不同的DataNode上以避免单点故障。
元数据管理:NameNode负责维护文件名、路径、副本数量等元数据信息,并通过编辑日志和文件系统镜像进行持久化存储。
3.2 容错性设计
副本冗余存储:通过多副本机制保证数据可靠性。
心跳检测:DataNode定期发送心跳信号,确保节点正常运行。
故障恢复:NameNode故障时,Secondary NameNode可用于恢复。
3.3 扩展性
动态添加DataNode:支持动态增加存储节点,轻松应对数据量增长。
4. 应用实例
4.1 互联网公司用户行为数据存储
数据收集:通过日志收集系统实时收集用户行为数据并写入HDFS。
数据存储:按规则分割和存储数据块,实现冗余存储。
数据分析:使用MapReduce、Spark等计算框架处理和分析数据。
结果展示:通过可视化工具展示分析结果,支持企业决策。
5. 解决小文件问题
5.1 合并小文件
手动合并:编写脚本或程序将多个小文件合并成一个大文件。
MapReduce作业:利用MapReduce框架并行处理大量数据提高合并效率。
HAR技术:将多个小文件打包成一个归档文件,类似zip格式。
Spark动态分区合并:自动合并较小分区减少小文件数量。
5.2 优化Hive配置
设置输入输出合并:通过参数在任务结束时合并小文件。
控制Map和Reduce数量:减少任务数量以减少小文件生成。
相关问题与解答
1. HDFS是否适合存储小文件?
答:HDFS主要针对大规模数据集进行优化,在处理小文件时可能会存在性能瓶颈,小文件会导致大量的元数据开销和NameNode性能下降,建议通过文件合并和配置优化来改善小文件存储性能。
2. HDFS如何保证数据的高可用性?
答:HDFS通过多种机制保障系统高可用性,包括数据块的冗余存储、DataNode的心跳检测、NameNode的故障恢复以及副本机制,这些机制共同确保了数据的可靠性和系统的稳定运行。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/563983.html
 微信扫一扫
微信扫一扫