

在使用Linux系统进行文本处理和数据分析时,grep命令无疑是一个非常强大的工具,它能够基于特定的模式或正则表达式来搜索符合特定条件的字符串或行,从而帮助用户快速定位和处理数据,下面将详细解析grep命令的使用方法、选项以及与其他命令的结合使用,以提供全面深入的理解:

1、基本用法
命令结构:grep的基本命令结构是:grep [选项] 模式 [文件...]。“模式”可以是普通的文本字符串或是复杂的正则表达式,用于在指定的文件中进行搜索。
基础示例:要在名为log.txt的文件中寻找包含“error”关键词的行,可以使用命令:grep 'error' log.txt。
2、重要选项
忽略大小写:使用i选项可以使搜索不区分大小写。grep i 'Error' log.txt。
反向选择:通过v选项,可以输出不包含指定模式的行。grep v 'debug' log.txt。
显示行号:n选项可以在输出中显示匹配行的行号。grep n 'error' log.txt。
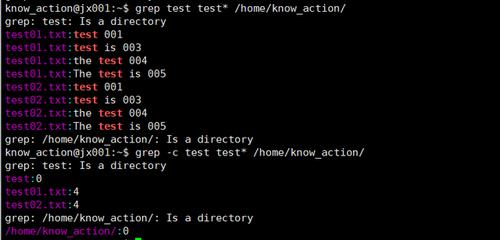
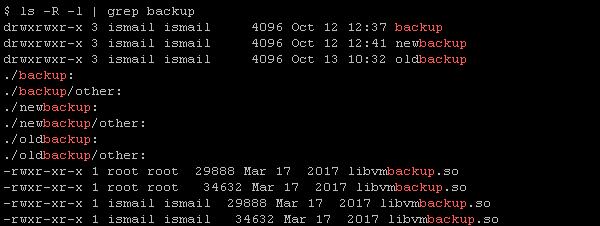
递归搜索:使用r选项可以递归地在目录及其子目录下的所有文件中进行搜索。grep r 'error' /var/log/。
3、正则表达式的使用
基本正则表达式(BRE)和扩展正则表达式(ERE):grep在默认情况下支持BRE,当使用E选项时,支持ERE。
元字符:.代表任意单个字符,^表示行首,$表示行尾,[]用于定义字符集合等。
4、高级应用
从文件中读取模式:使用f选项可以从指定文件中读取一系列正则表达式进行匹配。grep f patterns.txt log.txt。
多文件操作与输出重定向:grep可以处理多个文件,并将结果保存到新文件中。grep H 'error' *.log > errors_summary.txt。
5、实用技巧和结合其他命令
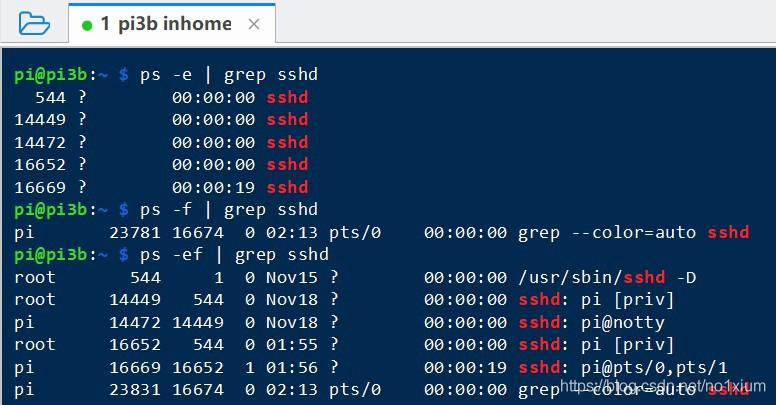
结合管道操作:grep常与其他命令如cat,ps,awk等结合使用,实现复杂的数据处理任务。ps ef | grep 'root'会列出所有包含“root”的进程信息。
grep命令提供了强大的文本搜索功能,通过熟练运用其各种选项和正则表达式,可以极大地提高文本处理的效率和准确性,无论是面对简单的文本搜索需求还是复杂的数据处理任务,合理使用grep都将是解决问题的有效方式。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/564859.html
 微信扫一扫
微信扫一扫