

python,import tensorflow as tf,from tensorflow.keras.models import Sequential,from tensorflow.keras.layers import LSTM, Dense,,model = Sequential(),model.add(LSTM(50, activation='relu', input_shape=(10, 1))),model.add(Dense(1)),model.compile(optimizer='adam', loss='mse'),``,,这个模型包含一个LSTM层和一个全连接层。LSTM层有50个单元,激活函数为ReLU。全连接层只有一个输出单元。模型使用Adam优化器和均方误差损失进行编译。使用TensorFlow实现LSTM的示例
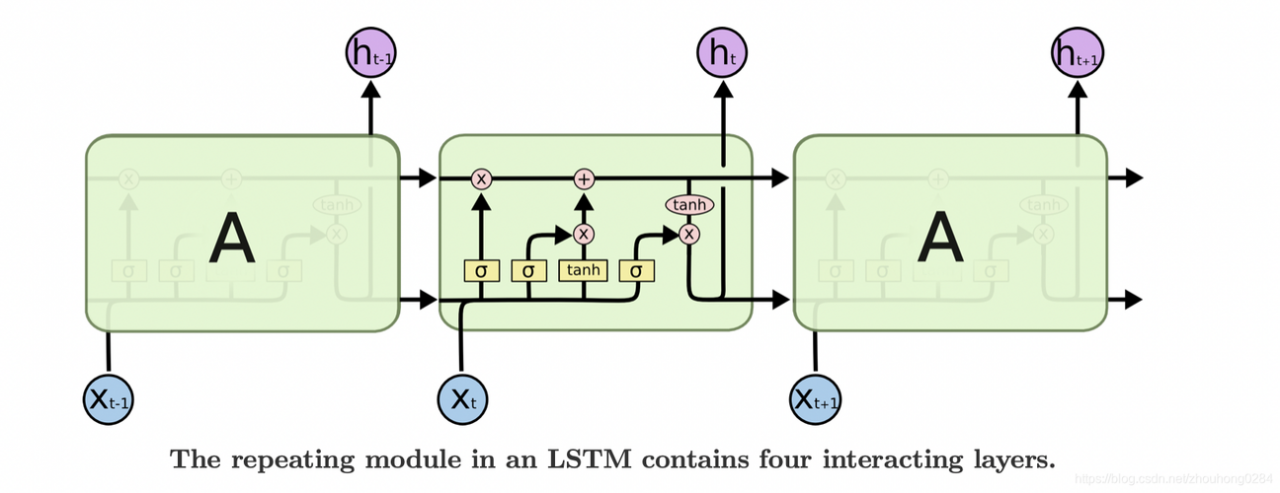

背景介绍
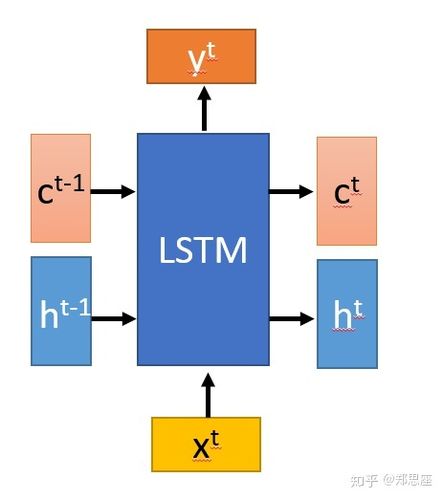
在深度学习领域,循环神经网络(RNN)及其变体如长短期记忆网络(LSTM)在处理序列数据方面显示出了强大的能力,特别是在自然语言处理、时间序列分析和语音识别等任务中,LSTM因其能够捕捉长期依赖关系而受到青睐,本教程将通过一个详细的TensorFlow示例来展示如何搭建和训练一个LSTM模型。
环境设置与数据准备
2.1 环境设置
确保您已经安装了TensorFlow,如果尚未安装,可以使用pip进行安装:
pip install tensorflow
2.2 数据准备
为了简化,我们将使用Keras内置的数据集:
from tensorflow.keras.datasets import imdb 加载数据集 (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
构建LSTM模型
3.1 数据预处理
对数据进行必要的预处理,包括归一化和形状调整以适应LSTM层:
import numpy as np
数据归一化
train_data = np.array(train_data).astype('float32')
test_data = np.array(test_data).astype('float32')
train_data /= np.max(train_data)
test_data /= np.max(test_data)
调整数据维度以符合LSTM层的输入要求
train_data = train_data.reshape((1, 200, 1))
test_data = test_data.reshape((1, 200, 1))
3.2 创建模型
使用TensorFlow定义LSTM模型:
from tensorflow.keras import Sequential from tensorflow.keras.layers import Embedding, LSTM, Dense model = Sequential() model.add(Embedding(10000, 32)) model.add(LSTM(32)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
模型训练与评估
4.1 模型训练
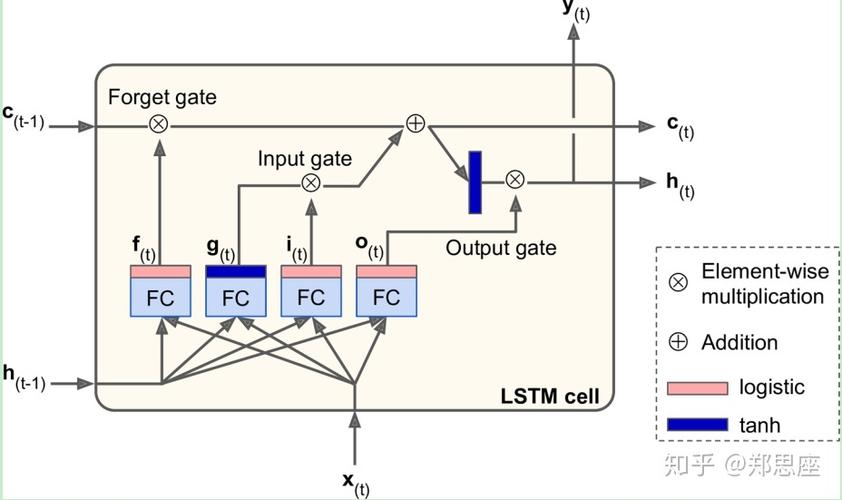
使用预处理过的数据对模型进行训练:
history = model.fit(train_data, train_labels, epochs=10, batch_size=512, validation_split=0.2)
4.2 模型评估
在测试集上评估模型性能:
loss, accuracy = model.evaluate(test_data, test_labels)
print("Test Accuracy: ", accuracy)
结果分析与优化
5.1 结果分析
分析训练过程中的损失和准确率曲线,查看模型是否出现过拟合或欠拟合现象,并据此调整模型结构或超参数。
5.2 模型优化
根据分析结果,可以尝试以下几种优化策略:
增加或减少LSTM单元的数量:调整模型复杂度。
改变优化器:尝试使用不同的优化器如adam或sgd。
调整学习率:通过调整学习率来影响训练速度和模型收敛。
添加正则化:如dropout层,以防止过拟合。
早停:在验证集的误差开始上升时停止训练,避免过拟合。
通过上述步骤,我们展示了如何使用TensorFlow从零开始构建和训练一个LSTM模型,虽然这个例子是简单的电影评论情感分类任务,但相同的流程可以应用于其他更复杂的序列数据处理问题。
相关问答
Q1: LSTM相比传统的RNN有什么优势?
A1: LSTM通过引入门控机制解决了传统RNN在处理长序列时的梯度消失/爆炸问题,使其能够捕捉长期的依赖关系。
Q2: 如何进一步优化LSTM模型的性能?
A2: 可以通过增加数据集的大小、调整网络结构、使用预训练的词嵌入、应用更先进的优化技术如batch normalization或layer normalization等方式来优化模型性能。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/564879.html
 微信扫一扫
微信扫一扫