

在Linux环境中编译并运行Spark程序需要以下步骤:

1、安装Java和Scala环境
2、下载Spark源码
3、编译Spark源码
4、运行Spark程序
1. 安装Java和Scala环境
确保你的系统中已经安装了Java和Scala,可以使用以下命令检查:
java version scala version
如果没有安装,可以使用以下命令进行安装(以Ubuntu为例):
sudo aptget update sudo aptget install defaultjdk sudo aptget install scala
2. 下载Spark源码
从Spark的官方网站下载源码包,或者使用Git克隆源码库,这里以下载源码包为例:
wget https://archive.apache.org/dist/spark/spark3.1.2/spark3.1.2binhadoop3.2.tgz
3. 编译Spark源码
解压源码包并进入目录:
tar xzf spark3.1.2binhadoop3.2.tgz cd spark3.1.2binhadoop3.2
编译Spark源码:
./build/mvn DskipTests clean package
编译完成后,会在assembly/target目录下生成一个sparkassembly*.jar文件,这是我们运行Spark程序需要的。
4. 运行Spark程序
编写一个简单的Spark程序,例如wordcount.py:
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
conf = SparkConf().setAppName("WordCount")
sc = SparkContext(conf=conf)
text_file = sc.textFile("hdfs://localhost:9000/user/hadoop/input")
word_counts = text_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
word_counts.saveAsTextFile("hdfs://localhost:9000/user/hadoop/output")
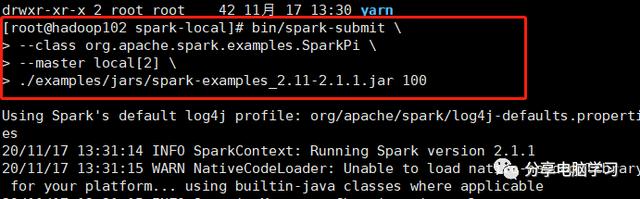
使用sparksubmit命令运行程序:
./bin/sparksubmit class org.apache.spark.deploy.SparkSubmit master local[4] /path/to/wordcount.py
注意:这里的local[4]表示使用4个本地线程运行程序,你可以根据实际需求调整。
运行成功后,你可以在HDFS的/user/hadoop/output目录下看到结果。
相关问答
Q1: 如果在编译Spark源码时遇到问题怎么办?
A1: 确保你的网络连接正常,因为编译过程中需要下载一些依赖,检查你的Java和Scala环境是否安装正确,如果问题仍然存在,可以查看编译过程中的错误日志,通常可以找到问题的线索,你还可以在Spark的官方论坛或GitHub仓库中寻求帮助。
Q2: 如何将Spark程序部署到集群上运行?
A2: 要将Spark程序部署到集群上运行,你需要修改sparksubmit命令中的master参数,如果你的集群使用Spark Standalone模式,可以将master参数设置为spark://<masterurl>:7077,你还需要将输入和输出路径更改为HDFS或其他分布式存储系统的路径,确保你的程序能够在集群环境中正常运行,例如处理数据分区、容错等问题。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/565256.html
 微信扫一扫
微信扫一扫