

逻辑回归是一种广泛应用于分类问题的统计方法,特别是用于处理因变量为二分类的问题,尽管名字中包含“回归”二字,但逻辑回归实际上是一种分类算法,主要用于预测某个事件的概率。
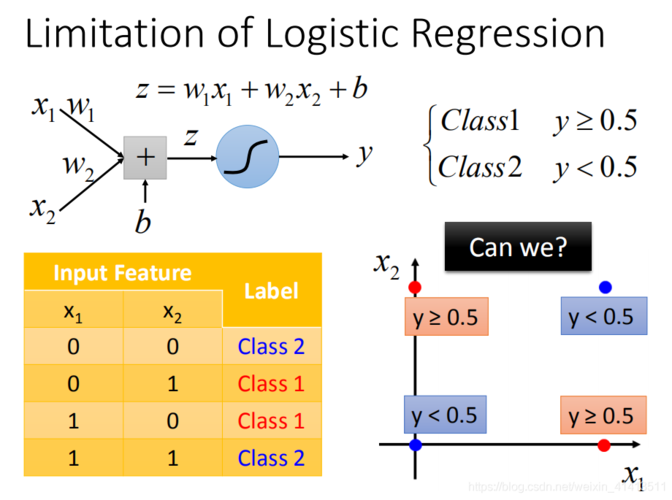

逻辑回归的基本原理
逻辑回归的核心在于应用一个逻辑函数(通常是sigmoid函数)将线性回归的输出值映射到一个概率值上,这个概率值表示某事件发生的可能性。
数学模型
在逻辑回归中,我们首先定义特征与输出之间的线性关系:
\[ z = w_0 + w_1x_1 + w_2x_2 + \ldots + w_nx_n \]
\(w_0, w_1, \ldots, w_n\) 是模型参数,\(x_1, x_2, \ldots, x_n\) 是特征变量。
通过应用sigmoid函数将线性组合的结果转换成概率值:
\[ \sigma(z) = \frac{1}{1 + e^{z}} \]
该函数的值域为(0, 1),可以解释为属于某一类的概率。
损失函数
逻辑回归使用对数损失(log loss)作为损失函数,也称为交叉熵损失,对于二分类问题,如果模型的预测值为\(y'\),实际标签为\(y\),则单个样本的对数损失定义为:
\[ L = (y \cdot \log(y') + (1 y) \cdot \log(1 y')) \]
整个训练集的损失函数是所有样本损失的总和。
优化算法
通常使用梯度下降或其变体来优化逻辑回归模型的参数,以最小化损失函数。
以下是使用Python和scikitlearn库实现逻辑回归的示例代码:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
加载数据集
iris = load_iris()
X = iris.data[:, :2] # 仅使用前两个特征进行简化
y = iris.target
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
创建并训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
预测和评估
y_pred = model.predict(X_test)
print("Accuracy on test set:", accuracy_score(y_test, y_pred))
单元表格
| 组件 | 描述 |
| 数据准备 | 选择适当的特征和目标变量 |
| 模型初始化 | 创建LogisticRegression实例 |
| 模型训练 | 使用训练数据拟合模型 |
| 预测 | 使用模型预测测试数据的结果 |
| 评估 | 计算预测结果的准确性或其他评估指标 |
相关问答
Q1: 逻辑回归和线性回归有何不同?
A1: 尽管两者都使用了线性方程来建模输入特征与输出之间的关系,但逻辑回归通过应用sigmoid函数将线性输出转换为概率值,主要用于分类任务;而线性回归直接输出一个连续值,用于回归任务。
Q2: 如何提高逻辑回归模型的性能?
A2: 可以通过以下方式提高性能:
特征工程:增加新的特征、移除无关特征或转换现有特征。
正则化:如L1和L2正则化,防止过拟合。
参数调优:调整模型参数,如正则化强度、学习率等。
数据预处理:标准化或归一化数据。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/565662.html
 微信扫一扫
微信扫一扫