

链式MapReduce,又称为多阶段MapReduce或级联MapReduce,是MapReduce编程模型的一个扩展,在传统的MapReduce中,数据处理流程分为两个阶段:Map阶段和Reduce阶段,但在实际应用中,某些复杂的数据处理任务可能需要多个Map和Reduce阶段才能完成,这就是链式MapReduce的概念。
链式MapReduce的基本概念
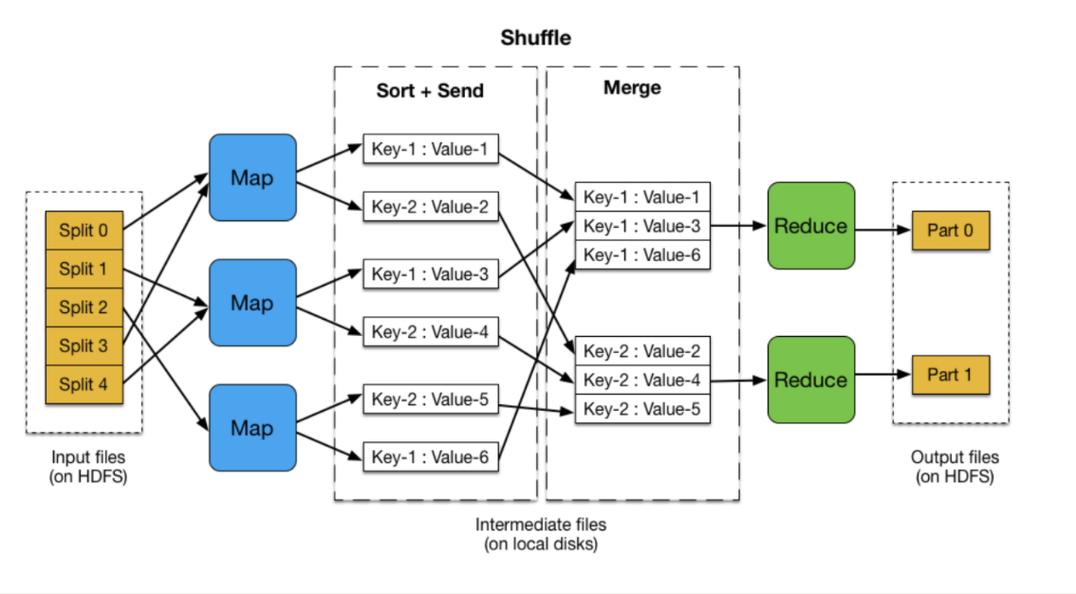
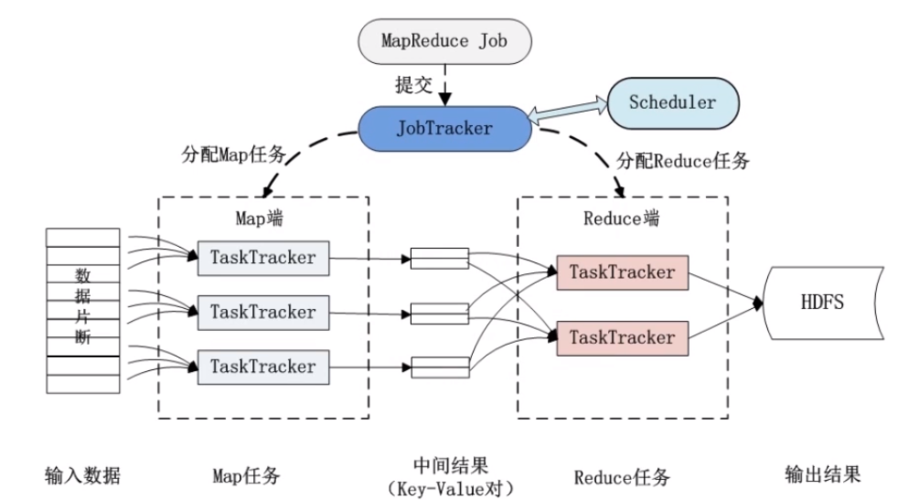
在链式MapReduce中,每个Map和Reduce阶段都可以视为一个单独的处理单元,这些处理单元可以按照一定的顺序连接起来,形成一个数据处理的流水线,每个阶段的输出作为下一个阶段的输入,从而形成数据流的连续传递和转换。
链式MapReduce的工作原理
1、输入数据:原始数据被输入到第一个Map阶段。
2、Map阶段:在每个Map阶段,数据会被分割成小块,然后并行地进行处理,每个Map任务会生成一组中间键值对。
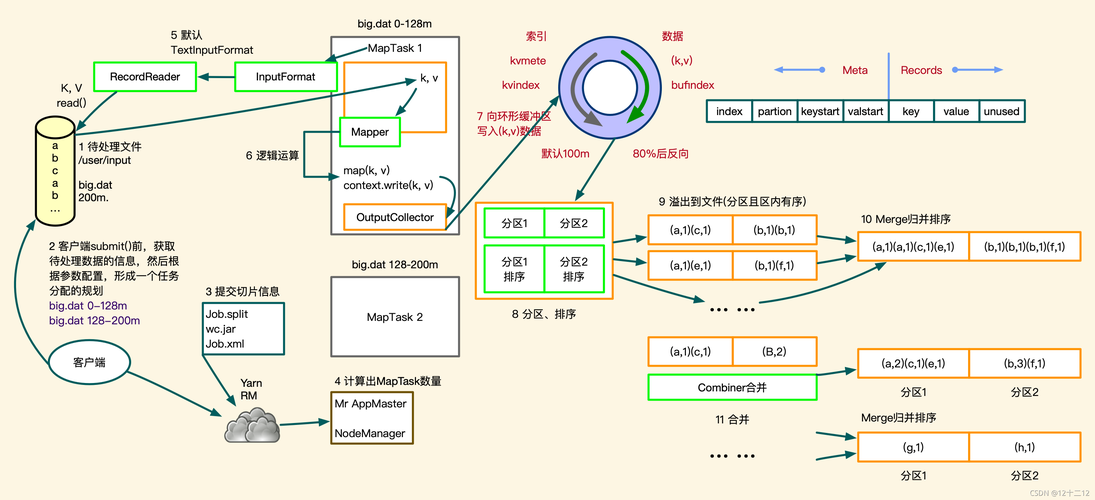
3、Shuffle阶段:Shuffle阶段负责将Map阶段的输出根据键值进行分组,并将它们传递给相应的Reduce任务。
4、Reduce阶段:在每个Reduce阶段,具有相同键的所有值会被聚合在一起,并进行处理以生成最终结果。
5、输出结果:最后一个Reduce阶段的输出就是整个链式MapReduce作业的结果。
链式MapReduce的优势
模块化:每个Map和Reduce阶段都可以独立设计,便于维护和测试。
灵活性:可以根据需要添加或移除处理阶段,以适应不同的数据处理需求。
可扩展性:通过增加更多的计算资源,可以水平扩展处理能力。
容错性:由于数据在各个阶段之间是独立的,因此单个阶段的失败不会导致整个作业失败。
链式MapReduce的挑战
数据传递开销:每个阶段之间的数据传递可能会引入额外的开销。
资源管理:需要合理分配和管理计算资源,以避免瓶颈和资源浪费。
调试复杂性:由于作业包含多个阶段,调试和优化可能更加复杂。
链式MapReduce的应用案例
假设我们有一个文本处理任务,需要先进行单词计数,然后统计每个单词的平均长度,这个任务可以通过链式MapReduce来实现:
1、第一阶段:Map函数读取文本文件,分割单词,并为每个单词生成一个键值对(单词,1)。
2、第一阶段的Reduce:Reduce函数接收相同单词的所有键值对,计算每个单词的出现次数。
3、第二阶段:Map函数读取第一阶段的输出,并为每个单词生成一个键值对(单词,单词长度)。
4、第二阶段的Reduce:Reduce函数接收相同单词的所有键值对,计算每个单词的平均长度。
示例代码(伪代码)
// 第一阶段 Map 函数
function map1(text):
words = split(text)
for word in words:
emit(word, 1)
// 第一阶段 Reduce 函数
function reduce1(word, values):
count = sum(values)
emit(word, count)
// 第二阶段 Map 函数
function map2(word, count):
emit(word, length(word))
// 第二阶段 Reduce 函数
function reduce2(word, lengths):
avg_length = sum(lengths) / count
emit(word, avg_length)
链式MapReduce的实现技术
链式MapReduce的实现通常依赖于大数据处理框架,如Hadoop、Spark等,这些框架提供了任务调度、资源管理和容错机制,使得链式MapReduce能够高效地运行在大规模数据集上。
性能优化技巧
合理设计Map和Reduce函数:确保每个函数尽可能简单,减少不必要的计算和数据传输。
调整资源分配:根据每个阶段的计算和数据量来分配合适的资源。
使用高效的数据结构:选择合适的数据结构可以减少内存消耗和提高处理速度。
优化Shuffle过程:Shuffle是MapReduce中最耗时的部分之一,可以通过压缩、合并等技术来优化。
相关工具和平台
Apache Hadoop:是一个开源框架,支持使用Java编写的MapReduce作业。
Apache Spark:提供了更高级的API和更快的执行速度,支持多种编程语言。
Apache Flink:是一个流处理和批处理框架,也支持链式MapReduce作业。
问题与解答
Q1: 链式MapReduce与传统MapReduce的主要区别是什么?
A1: 链式MapReduce与传统MapReduce的主要区别在于处理流程的复杂性,传统MapReduce只包含一个Map阶段和一个Reduce阶段,而链式MapReduce可以包含多个Map和Reduce阶段,这些阶段按顺序连接,形成数据处理的流水线。
Q2: 如何优化链式MapReduce的性能?
A2: 优化链式MapReduce的性能可以从以下几个方面入手:合理设计Map和Reduce函数以减少不必要的计算;调整资源分配以匹配每个阶段的计算需求;使用高效的数据结构来减少内存消耗和提高处理速度;优化Shuffle过程,例如通过压缩和合并来减少数据传输量。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/565798.html
 微信扫一扫
微信扫一扫