

使用当前活动缓存提升客户端与NameNode的连接性能
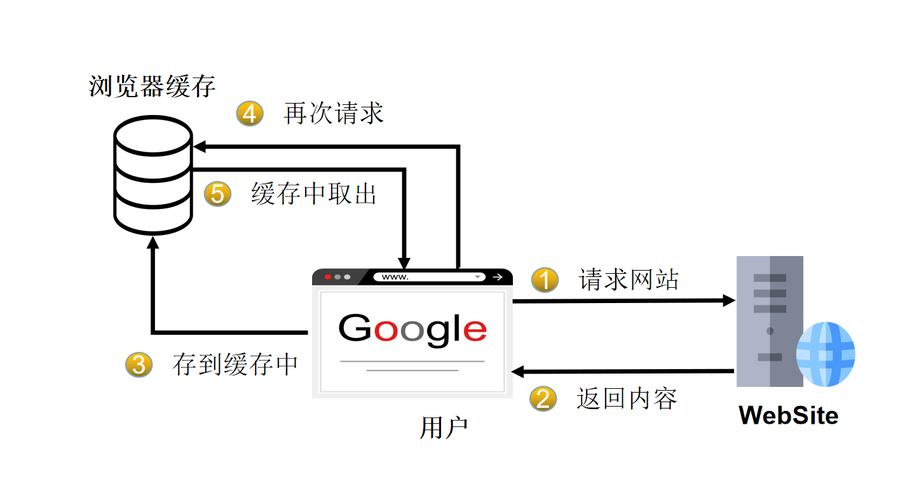

在Hadoop分布式文件系统(HDFS)中,NameNode是管理文件系统元数据的中心节点,当客户端需要访问文件或目录时,它必须首先与NameNode通信以获取必要的信息,为了提高这一过程的效率,可以利用客户端缓存机制来减少客户端与NameNode之间的通信次数,进而提升整体性能。
理解客户端缓存
客户端缓存是指在客户端本地存储一部分NameNode上的元数据信息,例如文件块的位置信息,这样,当客户端需要再次访问相同的文件或目录时,它可以首先查询本地缓存,而不是每次都直接向NameNode请求。
缓存的优势
减少网络延迟:通过本地缓存访问减少了对远程NameNode的依赖。

减轻NameNode负载:降低NameNode处理的请求数量,使其能够更有效地处理其他任务。
提升数据访问速度:快速从本地缓存检索数据,提高了数据处理效率。
实现客户端缓存
启用缓存
在Hadoop配置中,可以通过设置以下参数来启用客户端缓存:
dfs.client.read.shortcircuit.enabled=true dfs.domain.socket.path=/tmp
缓存策略
客户端缓存策略决定了哪些数据应该被缓存以及缓存多久,频繁访问的数据会被优先缓存,并且根据访问模式动态调整。
缓存更新
缓存数据需要定期与NameNode上的数据同步,以确保一致性,这通常是通过后台线程自动完成的。
相关问题与解答
Q1: 客户端缓存是否会占用大量磁盘空间?
A1: 客户端缓存确实会占用一些磁盘空间,但通常情况下这个空间是可管理的,并且相对于它带来的性能提升,这个代价是值得的,缓存的大小和位置可以通过配置参数进行调整。
Q2: 如果NameNode上的数据发生变化,客户端缓存如何保持最新?
A2: 客户端缓存通常会有一个后台线程负责与NameNode通信,检查缓存数据的有效性,如果发现NameNode上的数据已经更改,缓存中的数据将被相应地更新或失效,这样可以确保客户端总是能够访问到最新的数据。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/568338.html
 微信扫一扫
微信扫一扫