

大数据仓库技术_数据仓库
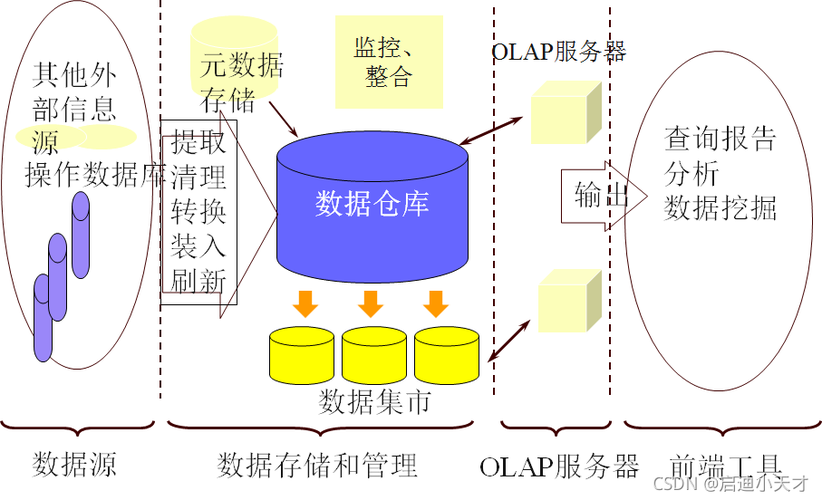

大数据仓库技术是用于存储、管理和分析大量数据的系统,随着数据量的爆炸性增长,传统的数据仓库已无法满足现代企业的需求,因此大数据仓库成为了解决此类问题的关键工具,本文将介绍大数据仓库的关键技术、架构设计以及应用场景。
关键特征
大数据仓库与传统数据仓库相比具有以下关键特征:
可扩展性: 能够处理持续增长的数据量。
高性能: 支持快速的数据处理和查询响应时间。
多样性: 能处理多种数据类型,包括结构化、半结构化和非结构化数据。
容错性: 系统稳健,能够在硬件故障时继续运行。
技术组件
大数据仓库通常包含以下几个技术组件:
1. 数据存储
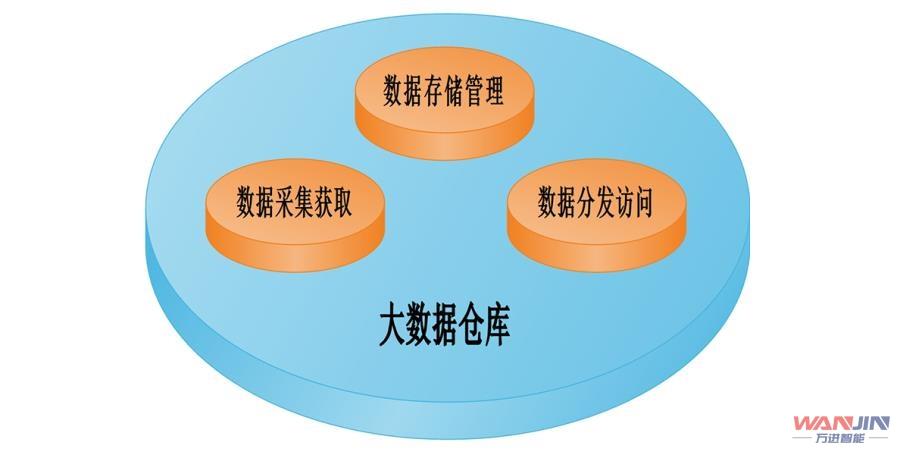
分布式文件系统: 如Hadoop的HDFS,提供高吞吐量的数据访问。
NoSQL数据库: 如Cassandra和MongoDB,适用于非结构化和半结构化数据。
2. 数据处理
批处理框架: 如Apache Hadoop的MapReduce。
流处理框架: 如Apache Kafka和Apache Flink,用于实时数据处理。
3. 数据管理
元数据管理: 管理数据的结构和组织信息。
数据质量管理: 确保数据的准确性和一致性。
4. 数据分析与查询
SQLonHadoop: 如Apache Hive和Presto,允许使用SQL查询大规模数据集。
数据可视化工具: 如Tableau和Power BI,帮助用户理解数据洞察。
架构设计
大数据仓库的架构设计通常遵循以下步骤:
1、需求分析: 确定业务需求和数据源。
2、数据集成: 将数据从不同来源导入到数据仓库。
3、数据存储: 选择合适的存储技术来保存数据。
4、数据处理: 实现数据的清洗、转换和加载(ETL)过程。
5、数据访问: 提供查询和分析接口。
6、维护与监控: 确保数据仓库的性能和稳定性。
应用场景
大数据仓库广泛应用于多个行业,包括:
金融服务: 风险分析、欺诈检测。
零售业: 客户行为分析、库存管理。
医疗保健: 患者数据管理、疾病预测。
社交媒体: 用户数据分析、趋势预测。
相关问题与解答
Q1: 大数据仓库与传统数据仓库有何不同?
A1: 大数据仓库在处理大规模、多样化和高速生成的数据方面具有更强的能力,它利用了分布式计算、NoSQL数据库和实时数据处理技术,而传统数据仓库通常依赖于集中式的关系型数据库管理系统(RDBMS),适合处理结构化数据且扩展性有限。
Q2: 如何确保大数据仓库的数据质量?
A2: 确保数据质量需要采取多项措施,包括实施数据清洗流程以消除错误和重复的数据,使用数据质量管理工具进行数据质量评估,以及建立数据治理策略来监控和管理数据的使用,定期对数据进行审计和检查也是保证数据质量的重要环节。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/568418.html
 微信扫一扫
微信扫一扫