

Lucene MapReduce
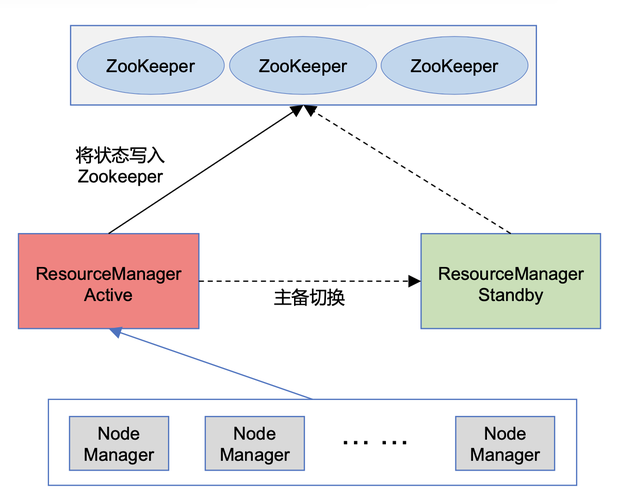

Lucene MapReduce 是一种基于 Apache Lucene 和 Hadoop MapReduce 的分布式搜索框架,它允许用户在大规模数据集上执行全文搜索操作,下面将详细介绍 Lucene MapReduce 的工作原理、架构以及如何在实际应用中使用它。
工作原理
Lucene MapReduce 结合了 Apache Lucene 的全文搜索能力和 Hadoop MapReduce 的分布式计算能力,它通过将数据分成多个分片,并在每个分片上执行 MapReduce 任务来实现分布式搜索,Lucene MapReduce 的工作流程如下:
1、数据预处理:将原始数据进行预处理,包括清洗、去重、分词等操作,以便后续的搜索操作。
2、分片:将预处理后的数据分成多个分片,每个分片包含一部分数据。
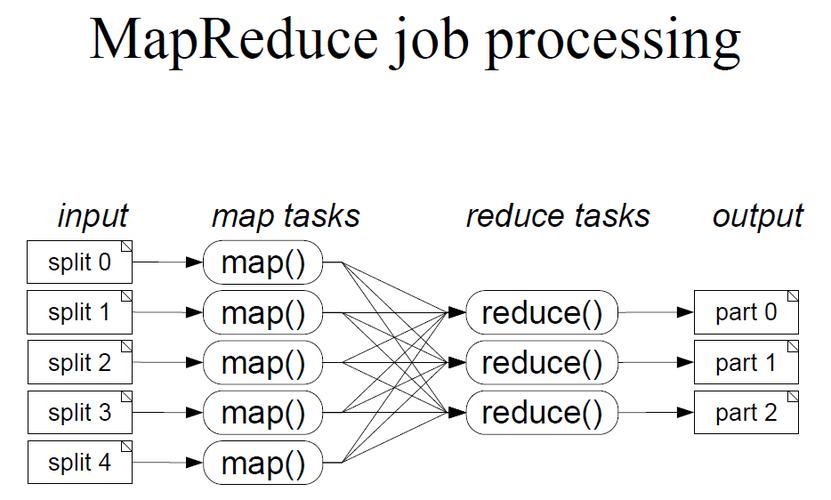
3、Map 阶段:在每个分片上执行 Map 任务,Map 任务的主要工作是将分片中的数据索引化,生成倒排索引。
4、Reduce 阶段:将各个分片上的倒排索引进行合并,生成全局的倒排索引。
5、搜索:利用生成的全局倒排索引执行搜索操作,返回符合条件的文档。
架构
Lucene MapReduce 的架构主要由以下几个组件组成:
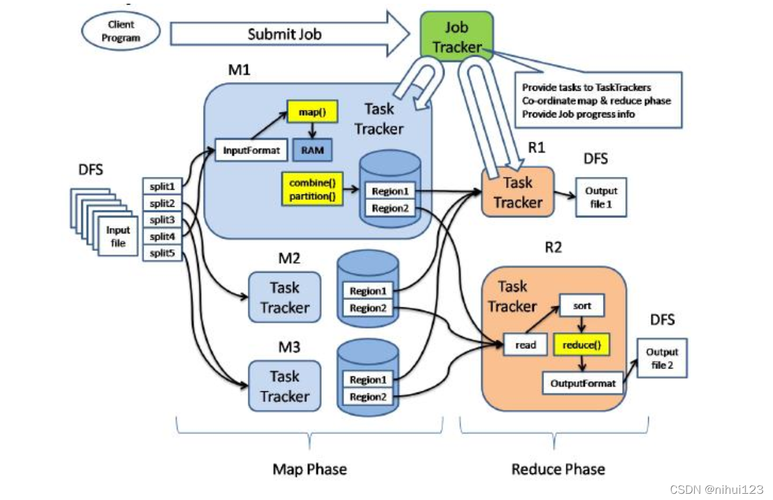
Client:客户端,负责提交搜索请求和接收搜索结果。
Master:主节点,负责协调整个搜索过程,包括分配 Map 和 Reduce 任务、合并倒排索引等。
Mapper:执行 Map 任务的工作节点,负责将分片中的数据索引化并生成倒排索引。
Reducer:执行 Reduce 任务的工作节点,负责将各个分片上的倒排索引进行合并。
这些组件之间通过 Hadoop 的分布式文件系统(HDFS)进行通信和数据传输。
使用示例
下面是一个简单的 Lucene MapReduce 的使用示例,用于在大规模文本数据上执行搜索操作:
1、数据预处理:对原始文本数据进行清洗、去重、分词等操作,生成预处理后的文本数据。
2、分片:将预处理后的文本数据分成多个分片,每个分片包含一部分数据。
3、Map 阶段:编写 Map 函数,用于将分片中的数据索引化并生成倒排索引,可以使用以下代码片段实现 Map 函数:
def map(document_id, text):
# 创建 Lucene 文档对象
doc = LuceneDocument(document_id, text)
# 对文档进行索引化
index_document(doc)
4、Reduce 阶段:编写 Reduce 函数,用于将各个分片上的倒排索引进行合并,可以使用以下代码片段实现 Reduce 函数:
def reduce(inverted_index_chunks):
# 合并倒排索引
merged_inverted_index = merge_inverted_index(inverted_index_chunks)
return merged_inverted_index
5、搜索:利用生成的全局倒排索引执行搜索操作,返回符合条件的文档,可以使用以下代码片段实现搜索功能:
def search(query):
# 执行搜索操作
results = perform_search(query)
return results
优点和局限性
Lucene MapReduce 具有以下优点:
高效性:通过将数据分成多个分片并在每个分片上并行执行 MapReduce 任务,Lucene MapReduce 可以高效地处理大规模数据集。
灵活性:Lucene MapReduce 提供了灵活的接口,可以根据具体需求自定义 Map 和 Reduce 函数,以满足不同的搜索需求。
可扩展性:由于基于 Hadoop MapReduce,Lucene MapReduce 可以很容易地扩展到大规模的集群上。
Lucene MapReduce 也存在一些局限性:
复杂性:Lucene MapReduce 的架构相对复杂,需要对 Hadoop MapReduce 和 Lucene 有一定的了解才能有效地使用。
学习曲线:对于初学者来说,理解和掌握 Lucene MapReduce 的使用和优化可能需要一定的学习和实践。
相关问题与解答
1、Lucene MapReduce 是否支持实时搜索?
答:Lucene MapReduce 本身不支持实时搜索,由于它基于批处理模型,需要在数据预处理和索引构建完成后才能执行搜索操作,如果需要实时搜索功能,可以考虑使用其他实时搜索引擎或结合其他技术实现。
2、Lucene MapReduce 如何处理数据更新?
答:Lucene MapReduce 主要适用于静态数据的搜索,对于数据更新的处理相对较弱,当数据发生更新时,需要重新执行整个数据处理和索引构建的过程,如果数据更新频繁,可能会影响搜索性能和效率。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/568634.html
 微信扫一扫
微信扫一扫