

Linux语音识别是一种将人类语音转换为文本的技术,实时语音识别是指能够即时处理和转换语音输入的能力,而不需要等待整个语音片段完成,在Linux系统中,有多种工具和库可以实现实时语音识别功能。


以下是一些常用的Linux语音识别工具和库:
1、CMU Sphinx:CMU Sphinx是一个开源的语音识别引擎,它基于隐马尔可夫模型(HMM)进行语音识别,它可以在实时环境下工作,并且支持多种语言。
2、Kaldi:Kaldi是一个用于语音识别和语音处理的开源软件套件,它提供了一套完整的工具链,包括特征提取、声学模型训练、解码器等,Kaldi也支持实时语音识别。
3、PocketSphinx:PocketSphinx是CMU Sphinx的一个轻量级版本,专门用于嵌入式设备和移动平台,它也支持实时语音识别。
4、Julius:Julius是一个开源的语音识别引擎,由日本国立信息通信研究所开发,它支持多种语言,并具有较好的实时性能。
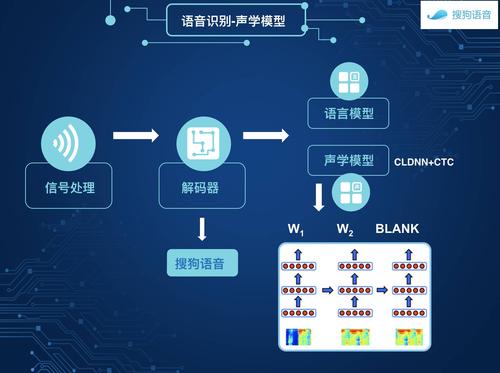
5、DeepSpeech:DeepSpeech是由谷歌开发的开源语音识别系统,使用深度学习技术进行语音转文本,虽然它主要用于离线语音识别,但也可以结合其他工具实现实时语音识别。
要实现实时语音识别,需要以下步骤:
1、音频采集:需要从麦克风或其他音频源获取实时音频数据,可以使用ALSA(Advanced Linux Sound Architecture)或其他音频库来实现音频采集。
2、音频预处理:对采集到的音频数据进行预处理,包括降噪、增益控制、预加重等操作,以提高语音识别的准确性。
3、特征提取:将预处理后的音频数据转换为适合语音识别的特征向量,常用的特征提取方法有梅尔频率倒谱系数(MFCC)、线性预测倒谱系数(LPCC)等。
4、声学模型:使用预先训练好的声学模型来识别语音特征,这些模型通常基于大量的语音数据进行训练,以学习不同发音和语言的特点。
5、解码器:将声学模型的输出转换为最终的文本结果,解码器可以使用搜索算法(如维特比算法)或深度学习模型(如循环神经网络)来进行解码。
6、实时反馈:将识别结果实时显示给用户,以便他们可以了解当前的语音识别状态。
需要注意的是,实时语音识别的性能受到多种因素的影响,包括硬件性能、网络延迟、背景噪音等,为了提高实时语音识别的准确性和稳定性,可能需要进行一些优化和调整。
问题1:如何安装和使用CMU Sphinx进行实时语音识别?
答案1:要在Linux上安装CMU Sphinx,可以使用以下命令:
sudo aptget install sphinxbase sudo aptget install pocketsphinx
安装完成后,可以使用pocketsphinx_continuous命令进行实时语音识别:
pocketsphinx_continuous hmm /usr/share/pocketsphinx/model/enus/enus lm /usr/share/pocketsphinx/model/enus/enus.lm dict /usr/share/pocketsphinx/model/enus/cmudictenus.dict
这将启动一个实时语音识别进程,并将识别结果输出到终端。
问题2:如何使用Kaldi进行实时语音识别?
答案2:要在Linux上安装Kaldi,可以参考官方文档中的安装指南,安装完成后,可以使用Kaldi的工具链进行实时语音识别,具体步骤如下:
1、准备音频数据和词汇表文件。
2、使用Kaldi的工具链进行特征提取、声学模型训练和解码。
3、运行解码器脚本,将实时音频数据传递给解码器进行识别。
具体的操作步骤较为复杂,建议参考Kaldi官方文档和教程进行学习和实践。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/569947.html
 微信扫一扫
微信扫一扫