

逻辑回归(Logistic Regression)是机器学习领域中一种非常流行的分类算法,尤其是用于解决二分类问题,它的核心思想是通过拟合一个逻辑函数来实现对样本的分类,虽然名字中带有“回归”二字,但它实际上是一种分类模型。

逻辑回归函数
逻辑回归使用了一个名为逻辑函数(或称为Sigmoid函数)的非线性函数来预测概率,逻辑函数的表达式为:
$$ \sigma(z) = \frac{1}{1 + e^{z}} $$
\( z \) 是线性函数的输出,通常表示为:
$$ z = \beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_nx_n $$

这里,\( x_1, x_2, ..., x_n \) 是特征变量,而 \( \beta_0, \beta_1, ..., \beta_n \) 是相应的模型参数。
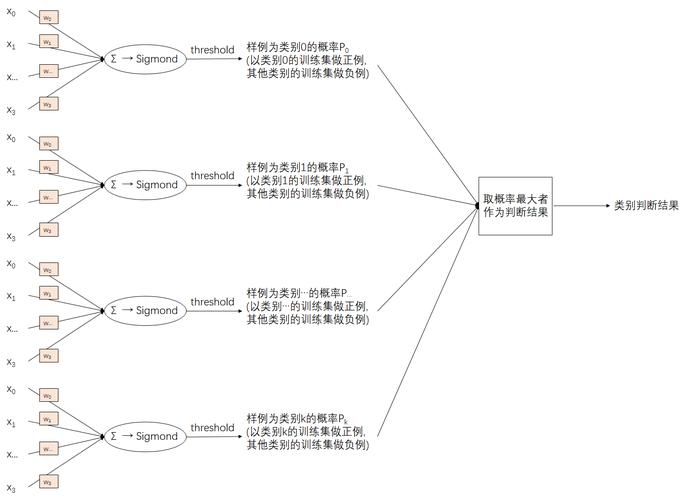
逻辑回归分类
在二分类问题中,逻辑回归模型的目标是估计给定输入特征时某个类别(通常是正类)的概率,如果这个概率超过0.5,则将该样本归类为正类;否则归类为负类。
参数估计
逻辑回归中的参数通常通过最大似然估计(MLE)方法进行估计,就是最大化以下似然函数:

$$ L(\beta) = \prod_{i=1}^{m} P(y_i | x_i; \beta) $$
\( y_i \) 是第 \( i \) 个样本的真实标签,\( x_i \) 是特征向量,\( m \) 是样本数量,\( P(y | x; \beta) \) 是在给定参数 \( \beta \) 下观测到 \( y \) 的概率。
由于直接最大化似然函数比较困难,通常会取其对数形式,得到对数似然函数:
$$ l(\beta) = \sum_{i=1}^{m} \left[ y_i \log(\sigma(z_i)) + (1 y_i) \log(1 \sigma(z_i)) \right] $$
然后通过梯度上升或牛顿法等优化算法来求解最优的参数 \( \beta \)。
模型评估
逻辑回归模型的性能可以通过多种指标来评估,包括准确率、召回率、精确度和F1分数等,还可以使用接收者操作特征曲线(ROC Curve)和AUC(Area Under the Curve)来评价模型的整体性能。
单元表格
下面是一个简化的示例表格,展示了如何根据不同的输入特征和对应的逻辑回归模型参数计算预测概率。
| 样本编号 | 特征1 (\( x_1 \)) | 特征2 (\( x_2 \)) | β0 | β1 | β2 | 预测概率 (\( \hat{y} \)) |
| 1 | 0.5 | 1.2 | 0.3 | 0.8 | 0.4 | $ \frac{1}{1 + e^{(0.3 + 0.8 \times 0.5 0.4 \times 1.2)}} $ |
| 2 | 0.2 | 0.9 | 0.3 | 0.8 | 0.4 | $ \frac{1}{1 + e^{(0.3 + 0.8 \times 0.2 0.4 \times 0.9)}} $ |
相关的问题与解答
Q1: 逻辑回归是否适用于多分类问题?
A1: 是的,逻辑回归可以扩展到多分类问题,对于K类分类问题,可以使用多元逻辑回归(Softmax回归),其中每个类别都有一个输出单元,输出单元的值被解释为样本属于该类的条件概率。
Q2: 逻辑回归模型如何处理不平衡数据集?
A2: 处理不平衡数据集时,逻辑回归模型可能会偏向多数类,为了解决这个问题,可以采用过采样少数类、欠采样多数类、使用不同的损失函数(如焦点损失)、或者调整决策阈值等策略,也可以通过引入成本敏感的学习,给错误分类的样本分配不同的权重来改善模型性能。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/570535.html
 微信扫一扫
微信扫一扫