

list_indexes命令查看所有已创建的二级索引。,3. 如果需要查看特定表的二级索引,可以使用describe '表名'命令。,,这样,你就可以获取到HBase数据库中的二级索引列表。在探讨HBase数据库中二级索引列表的查询操作之前,理解HBase及其二级索引的基本概念是至关重要的,HBase是一种分布式、可扩展的大数据存储系统,它位于Hadoop生态系统中,并常常被用作大规模的数据集存储解决方案,HBase通过其内在的行键(rowkey)高效地支持主键查询,但在面对复杂查询需求时则显得力不从心,为了解决这个问题,二级索引应运而生,具体分析如下:

1、创建二级索引的方式
利用Inceptor SQL引擎:通过Inceptor分布式SQL引擎与HBase交互,可以创建二级索引,执行全局索引的创建操作,命令为create global index index_num on hyper_table(num)。
HBase shell中直接创建:在HBase shell中,可以通过指定相关参数来直接创建二级索引,示例命令为add _index 'hyper_table', 'index_num', 'COMBINE_INDEX|INDEXED=f:q2:8|rowKey:rowKey:9'。
2、二级索引的工作原理
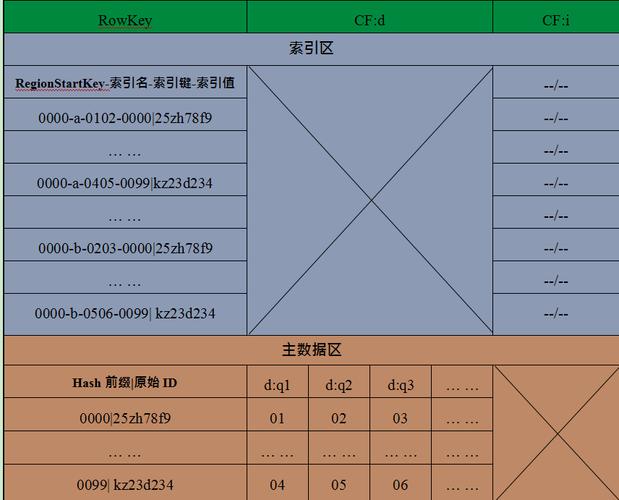
映射关系的构建:二级索引本质上是建立列值与行键之间的映射关系,如对某列F:C1建立索引,实际上是创建了类似C11>RK1这样的映射。
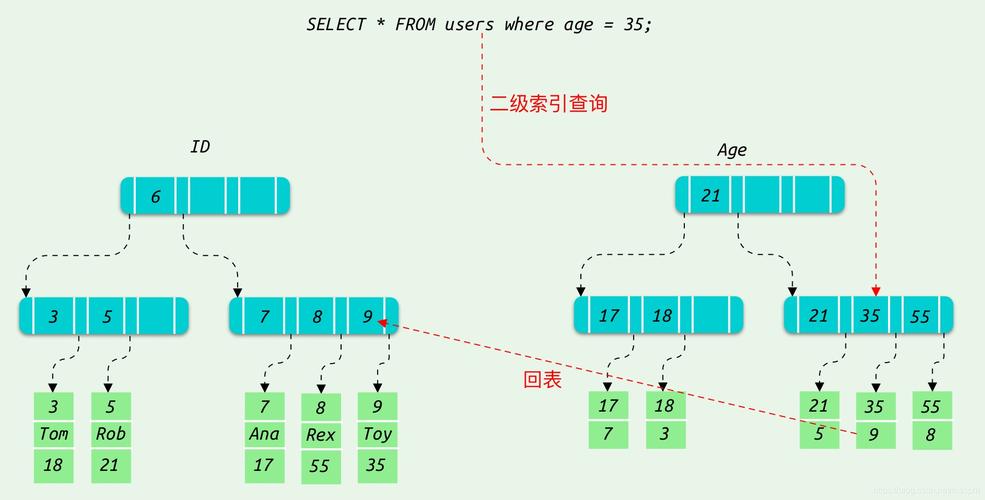
查询过程:当需要根据特定列值(如C1=C11)查询其他列(如F:C2)时,首先在索引数据中找到对应的RK(RK1),再根据此RK查询所需列的值。
3、使用注意事项与约束
行键一致性:二级索引表的行键必须与主表的行键相同,这是保证两者之间关联的基础。
索引设计考虑:每张索引表作为独立的HBase表,其主键(rowkey)设计决定了支持的查询模式,多种组织方式的rowkey能够支持更复杂的查询需求。
4、基于Solr的多条件查询
索引建立:涉及条件过滤的字段和rowkey在Solr中建立索引,以便快速获得符合条件的rowkey值。
查询执行:通过Solr查询符合多个条件的rowkey之后,再在HBase中进行精确查询,从而提高查询效率。
5、增强版二级索引的特点
全局二级索引:增强版二级索引被视为全局二级索引,每个索引表都是独立的HBase表,具有独立存在的特质。
多种查询模式的支持:通过不同的rowkey设计,全局二级索引能够支持多种查询模式,提高数据查询的灵活性和效率。
主要聚焦于HBase数据库中二级索引的创建、工作原理、使用注意事项以及基于Solr的多条件查询方法,将提出两个与主题紧密相关的问题,并进行解答。
问题1: HBase中的二级索引是否会影响写操作的性能?
解答: 是的,二级索引在提高读操作效率的同时可能会对写操作性能产生一定影响,因为每次写入数据时,不仅需要更新基表(原始表),还需要更新相应的索引表,这增加了额外的写入负担,在实际应用中,需要根据业务需求权衡读写性能,决定是否使用二级索引及其使用策略。
问题2: 如何选择合适的索引策略以优化HBase查询?
解答: 选择合适索引策略应考虑以下因素:明确查询模式,了解数据访问的模式有助于确定哪些列需要建立索引;考虑数据规模与更新频率,大规模或高更新频率的数据可能需要更精细的索引设计以避免性能瓶颈;考虑使用组合索引或多条件查询工具如Solr,对于复杂的查询需求,这些工具能显著提升查询效率。
对HBase数据库中二级索引的操作和应用有了全面的解读,同时也针对可能遇到的问题提供了解答,利用二级索引可以大幅优化HBase的数据查询效率,但也需要细心规划,以确保不会因索引维护而严重影响写操作性能。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/570787.html
 微信扫一扫
微信扫一扫