

ClickHouse是一个开源的列式数据库管理系统(DBMS),专为在线分析处理(OLAP)而设计,它能够高效地存储和查询大规模的数据,尤其擅长处理时间序列数据,ClickHouse以其高速查询性能、高数据压缩率和易用性著称,在业界被广泛应用。
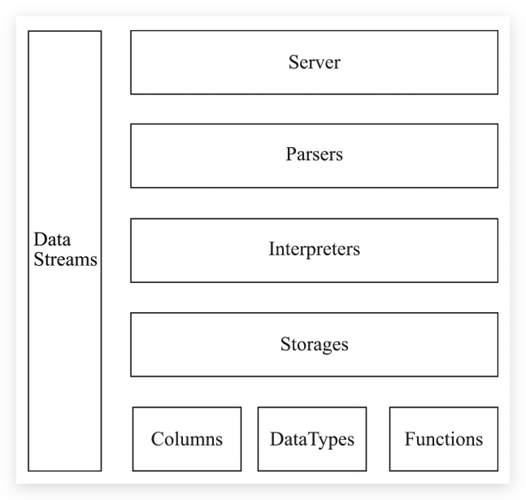

基本原理
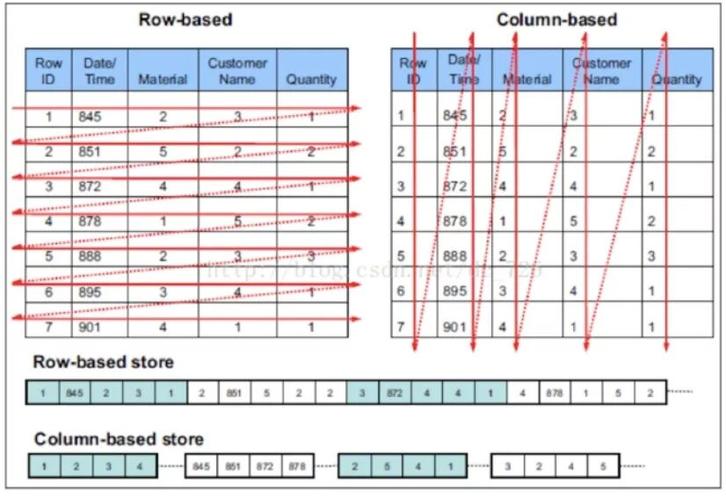
1. 列式存储
与行式数据库不同,ClickHouse将数据按列进行存储,这意味着同一列的数据会被连续存储在一起,而不是将一行的所有列数据连续存储,这样做的好处是,在进行数据分析时通常只需要读取部分列,列式存储可以显著减少I/O操作,提高查询效率。
2. 数据压缩
ClickHouse使用多种数据压缩算法来减少物理存储空间的需求,包括LZ4、ZSTD等,由于同列数据具有相似性,压缩效果非常好,这进一步降低了存储成本并提升了查询速度。
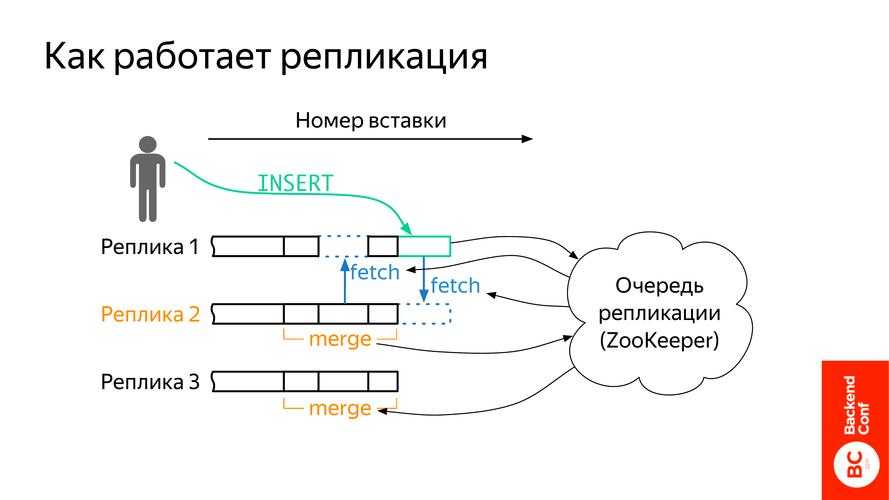
3. 分布式处理
ClickHouse支持分布式数据处理,可以通过多个节点的水平扩展来提升查询性能,它使用分片(shard)和复制(replication)的概念来实现数据的冗余和负载均衡。
4. 索引
ClickHouse支持多种索引类型,如主键索引、排序键索引和非主键索引,这些索引有助于快速定位到需要查询的数据,从而加速查询过程。
5. 向量引擎
ClickHouse的查询执行基于向量引擎,该引擎针对列式数据进行了优化,能够以向量化的方式处理数据,进一步提高了数据处理的速度。
6. SQL支持
ClickHouse支持ANSI SQL的一个子集,使得用户可以使用熟悉的SQL语法来进行数据查询和操作,它还提供了丰富的函数和操作符来满足复杂的分析需求。
7. 内存管理
ClickHouse有一套高效的内存管理机制,它可以控制内存的使用,防止单个查询消耗过多内存导致系统崩溃。
8. 容错性
ClickHouse设计了容错机制,即使部分节点发生故障,整个系统仍然可以继续运行。
架构组件
节点 (Node): ClickHouse的基本工作单位,每个节点可以独立工作或作为分布式集群的一部分。
副本 (Replica): 数据的完整拷贝,用于提高数据的可用性和耐故障能力。
分片 (Shard): 数据水平分割的单元,每个分片包含整体数据的一部分。
集群 (Cluster): 由多个节点组成的逻辑单位,提供统一的访问接口和数据管理功能。
查询流程
1、客户端发送SQL查询到ClickHouse服务器。
2、ClickHouse解析查询,并生成查询计划。
3、根据查询计划,ClickHouse从磁盘读取必要的列数据。
4、数据在内存中进行聚合和计算。
5、最终结果返回给客户端。
性能优化
硬件选择: 使用快速的SSD硬盘和足够的内存可以提高查询性能。
表结构设计: 合理设计表结构和索引可以加快数据检索速度。
查询优化: 避免全表扫描,利用索引和分区来缩小查询范围。
并发控制: 合理设置查询并发数,避免系统过载。
应用场景
日志分析: 大规模日志数据的存储和实时分析。
时间序列数据: 监控指标、金融数据等时间序列数据的高效存储和查询。
广告科技: 实时竞价、用户行为分析等。
商业智能: 快速响应的商业报表和仪表板。
相关技术比较
与其它数据库相比,如MySQL、PostgreSQL等传统关系型数据库,ClickHouse在OLAP场景下的性能优势明显,尤其是在处理大量数据时的查询速度和资源效率,对于事务处理密集型的OLTP场景,则可能不是最佳选择。
问题与解答
Q1: ClickHouse适合用来做实时事务处理吗?
A1: 不适合,ClickHouse是为OLAP设计的,它缺乏事务支持和复杂的一致性保证,因此不适合需要强一致性和频繁写操作的OLTP场景。
Q2: 如果需要对ClickHouse进行水平扩展,应该关注哪些因素?
A2: 进行水平扩展时,应考虑数据分片策略、查询负载分布、网络带宽和延迟、以及系统的容错和备份机制,应用层的适配也很重要,以确保查询可以有效地分布在各个节点上执行。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/571603.html
 微信扫一扫
微信扫一扫