

在数据分析和统计学中,数据可以大致分为两类:离散数据(discrete data)和连续数据(continuous data),理解两者的区别对于正确处理和分析数据至关重要,本文将深入探讨这两种类型的数据,并讨论何时以及如何将连续数据离散化。

离散数据 (discrete data)
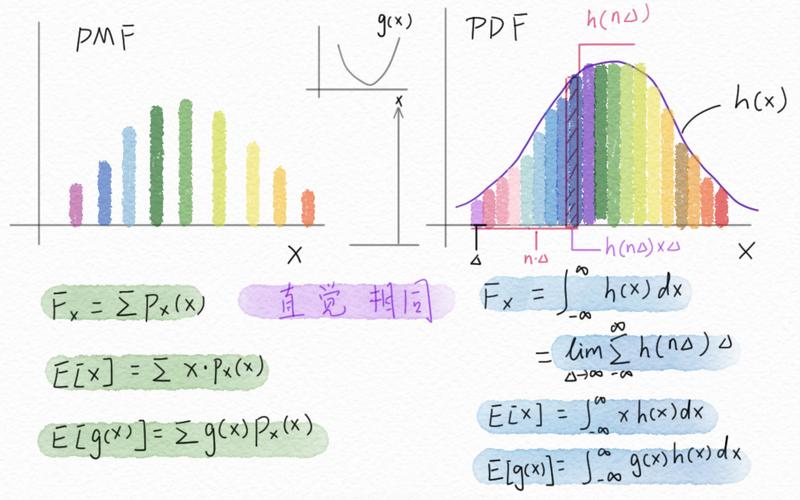
离散数据指的是那些只能取特定值的数据,通常是整数,并且它们之间有明确的间隔,一个家庭的孩子数量、某项考试的得分、或者一年内某人看电影的次数都是离散数据的例子,离散数据可以分为两种类型:
1、计数数据 表示计数或整数次数,比如学生人数、汽车数量等。
2、顺序数据 具有自然或人为定义的顺序,但差距不固定,如考试成绩等级(a, b, c, d, f)。
离散数据通常用直方图来展示,其中每个柱子代表特定值的频率。
连续数据 (continuous data)
与离散数据相对的是连续数据,它指的是可以在任意两个数值之间取得无限多个可能值的数据,连续数据可以是任何实数,包括分数和小数,典型的连续数据包括身高、体重、时间和温度等。
连续数据的分布常常用概率密度函数(pdf)来描述,并用直方图或曲线图来可视化,由于连续数据的值范围是无限的,因此直方图中的柱子实际上是对数据的一个近似表示,而曲线图则提供了更平滑的视图。
离散化 (discretization)
在某些情况下,将连续数据转换为离散数据的过程称为离散化,这可以通过多种方法实现,包括:
分箱 (binning):将连续的范围分成几个区间,并将每个区间内的所有值都归为同一类别。
阈值法:设定特定的阈值,根据值是否超过这些阈值来分类。
聚类:使用聚类算法将数据点分组,每组代表一个离散的类别。
离散化的原因可能包括简化模型、提高计算效率、解决存储限制问题,或是为了更好地适应某些只适用于离散数据的算法。
单元表格:离散化方法比较
| 方法 | 描述 | 优点 | 缺点 |
| 分箱 | 将连续范围分成若干个区间 | 简单易行,易于理解 | 可能会丢失一些信息 |
| 阈值法 | 根据预设阈值进行分类 | 快速且直接,适用于有明显界限的情况 | 需要先验知识来确定合适的阈值 |
| 聚类 | 使用算法自动分组 | 能够发现数据中的结构,适用于复杂数据集 | 需要选择适当的聚类算法和参数 |
在数据分析过程中,了解数据的类型及其特性对于采取正确的统计方法和分析手段至关重要,离散数据和连续数据各有其特点和适用范围,而离散化是连接这两种数据类型的桥梁,使得我们可以更加灵活地处理各种数据问题。
相关问题与解答
q1: 离散化是否会损失信息,如果是的话,如何减少这种损失?
a1: 是的,离散化过程可能会导致信息的丢失,因为它将一定范围内的所有连续值归为同一个类别,为了减少信息损失,可以采用以下策略:
选择合适的离散化方法,确保它适合当前数据的特性。
使用足够多的类别以保留更多的原始信息。
在离散化之前进行数据清洗和预处理,以确保数据的准确性和一致性。
q2: 离散化后的数据是否可以恢复成连续数据,如果可以,该如何操作?
a2: 一旦数据被离散化,原始的连续信息就会丢失,因此无法完全恢复到其原始的连续状态,可以尝试通过插值或拟合的方法来估计原始数据的分布,可以使用多项式拟合、样条插值或其他统计方法来近似原始数据的连续分布,这样得到的连续数据只是基于离散数据的估计,并不等同于原始数据。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/571711.html
 微信扫一扫
微信扫一扫