

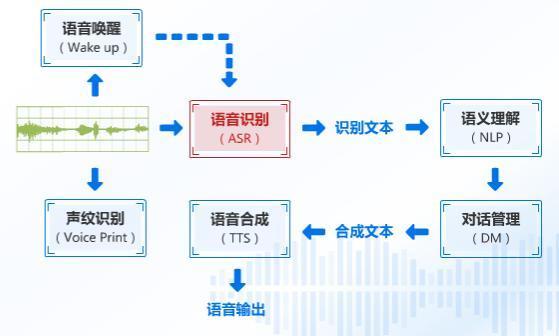
流式语音识别(Streaming Speech Recognition)是一种实时或接近实时的语音到文本转换技术,它允许用户在说话时连续上传语音数据,而无需等待语音输入完全结束,这种技术对于需要快速响应的应用非常重要,如交互式对话系统、实时字幕生成、语音控制的接口等。

工作原理
流式语音识别通常涉及以下几个步骤:
1、音频采集:通过麦克风或其他音频输入设备捕获语音。
2、预处理:对原始音频信号进行降噪、回声消除和增益控制等处理,以提高识别准确性。
3、特征提取:从处理过的音频中提取有用的特征,如频谱特征、梅尔频率倒谱系数(MFCC)等。
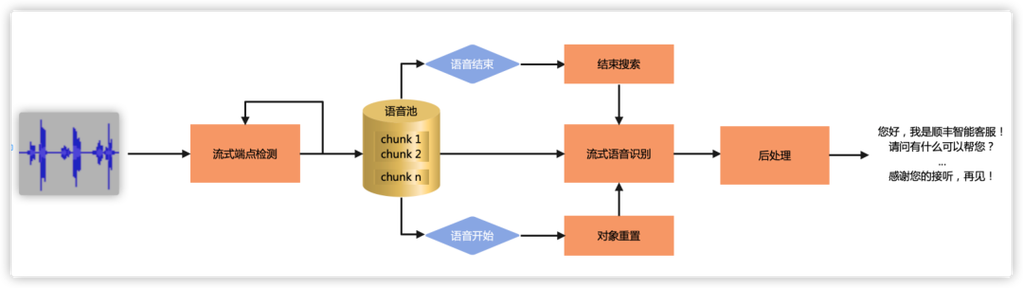
4、模型预测:使用深度学习模型(如循环神经网络RNN、长短期记忆网络LSTM、门控循环单元GRU或Transformer架构)对提取的特征进行实时分析,预测出对应的文字。
5、后处理:包括语言模型的整合、标点符号的添加、大小写校正等,使最终输出的文本更加流畅和准确。
技术挑战
延迟与准确性的平衡:减少延迟同时保持高准确性是技术上的一个挑战。
资源限制:流式处理需要在有限的计算资源下完成,这对算法的效率提出了更高要求。
噪声和口音的处理:在各种环境下都能准确识别语音,尤其是有背景噪音或不同口音的情况下。
应用示例
实时字幕生成:为视频会议或直播提供实时的文字记录。
交互式语音助手:如智能音箱,可以即时响应用户的指令。
辅助技术:为听力障碍者提供即时语音转写服务。
性能评估
评估流式语音识别系统的性能通常考虑以下指标:
字错误率(Word Error Rate, WER):衡量识别结果与实际文本之间的差异。
实时因子(RealTime Factor, RTF):处理时间与原始音频长度的比例,用于评估系统的响应速度。
吞吐量(Throughput):单位时间内能够处理的数据量。
表格归纳
| 组件 | 功能 | 技术/工具 |
| 音频采集 | 捕获语音输入 | 麦克风、音频接口 |
| 预处理 | 提升音频质量,准备后续处理 | 降噪、回声消除 |
| 特征提取 | 提取音频的关键信息以供模型分析 | MFCC、频谱特征 |
| 模型预测 | 利用AI模型进行语音识别 | RNN、LSTM、GRU、Transformer |
| 后处理 | 优化识别结果的可读性 | 语言模型、标点符号添加、大小写校正 |
相关Q&A
Q1: 流式语音识别与传统批处理语音识别有何区别?
A1: 流式语音识别能够在语音输入的同时进行识别处理,实现实时或近实时的反馈,而传统批处理语音识别需要等待整个语音输入结束后才开始处理,这导致较长的延迟。
Q2: 流式语音识别技术在资源受限的设备上如何实现?
A2: 在资源受限的设备上实现流式语音识别通常需要优化模型和算法,比如使用更轻量级的网络结构、量化、剪枝等技术来减少计算需求,以及采用边缘计算来分担中心服务器的负载。
这些技术和策略共同构成了流式语音识别的基础,使其成为许多现代应用不可或缺的一部分,随着技术的不断进步,我们可以预期流式语音识别将变得更加准确和普遍,为用户提供更加自然和无缝的交互体验。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/574807.html
 微信扫一扫
微信扫一扫