

在Linux系统中,内核异常事件分析是一个重要的诊断手段,用于解决系统崩溃、性能下降等问题,本文旨在提供一份详细的指南,以帮助理解和分析Linux内核中的异常事件。
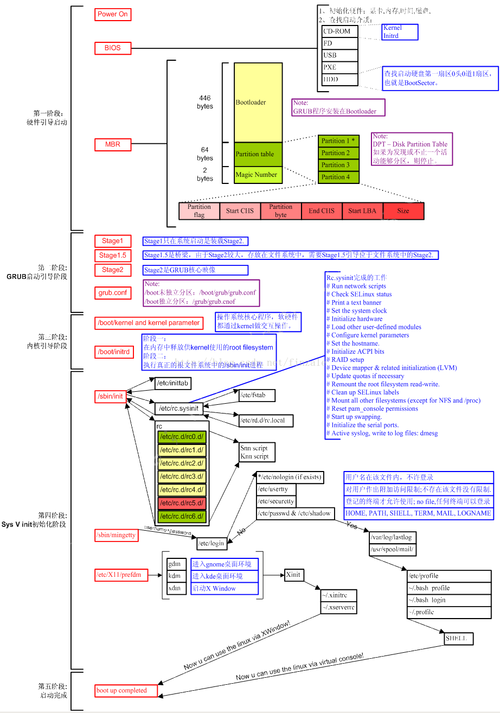
原理与方法
1. 异常原因识别
当Linux内核触发到某种异常情况时,它会运行kernel_panic函数,并尽可能把异常发生时获取的全部信息打印出来,导致异常的原因多种多样,包括但不限于空指针异常、内存访问越界等,通过分析异常打印的调用信息,可以追踪到触发kernel_panic的原因。
2. 统一异常框架(UKFEF)
为了更系统地处理和分析异常事件,Alibaba Cloud Linux 3引入了统一内核异常框架(UKFEF),该框架用于统计可能导致风险的系统异常事件,并以统一的格式输出事件报告,UKFEF能够统计的事件包括CPU异常、内存错误等,其报告输出形式为结构化的日志信息,便于后续分析。
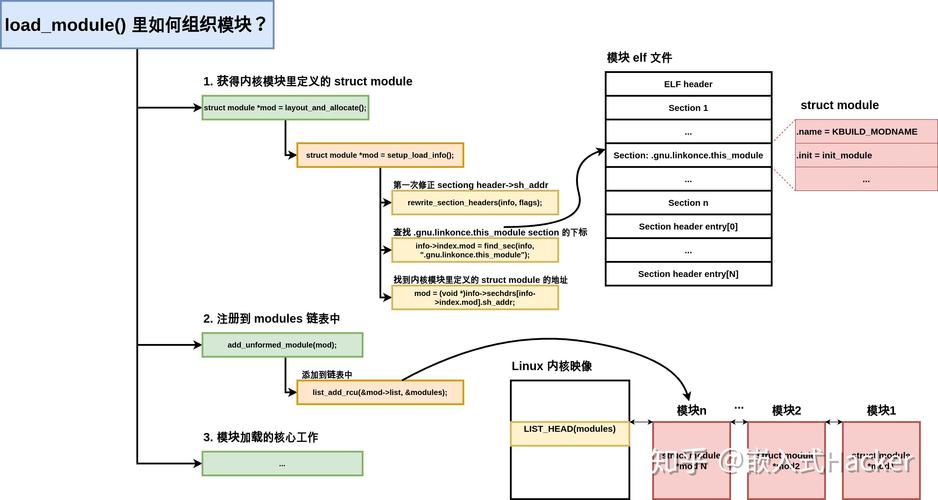
3. 捕获内核异常事件
对于Linux驱动或内核的开发者来说,获取并响应内核的异常事件至关重要,记录异常时的日志或dump出堆栈信息来帮助分析系统发生异常的原因,开发者可以通过注册异常处理函数,捕获如内核halt、restart等事件,进行相应的处理。
4. 使用Crash工具
crash是Linux内核崩溃调试工具,用于分析内核崩溃转储文件,通过加载vmcore文件和内核映像,管理员可以查看系统状态、调用栈、内存布局等信息。crash提供了GDBlike的交互式CLI,使得分析过程更加直观和方便。
分析流程
1、信息收集:首先需要确保系统在出现异常时能生成足够的信息,如开启UKFEF框架或配置内核以生成vmcore文件。
2、初步定位:通过分析异常信息输出或使用crash等工具,初步定位异常发生的上下文和可能的原因。
3、深入分析:根据初步定位的结果,深入分析相关的数据结构、代码逻辑等,以确定异常的根本原因。
4、解决方案:找到异常原因后,制定并实施解决方案,可能包括代码修复、配置调整等。
实践建议
持续监控:在生产环境中,持续监控系统日志和异常报告,及时发现并处理异常事件。
测试环境复现:尽量在测试环境中复现异常事件,以便更安全、准确地分析问题。
知识更新:随着Linux内核版本的更新,异常处理机制和工具也会发生变化,保持知识更新是必要的。
Linux内核异常事件的分析是一个系统性的工作,需要综合运用多种工具和方法,通过理解异常产生的原理,利用UKFEF等框架和crash等工具,可以有效地定位和解决内核异常,保障系统的稳定性和安全性。
相关问题解答
1、问:如何配置Linux内核以生成vmcore文件?
答:配置Linux内核生成vmcore文件通常需要在启动参数中加入 crashkernel=参数,指定保留内存的大小,还需要确保系统有足够的空闲内存来存放vmcore文件。
2、问:使用crash工具分析vmcore文件时应注意什么?
答:使用crash分析vmcore文件时,需要注意内核版本与crash工具的兼容性,由于vmcore文件可能非常大,分析时应确保有足够的磁盘空间。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/577365.html
 微信扫一扫
微信扫一扫 