

MapReduce框架与MapReduce应用开发常用概念
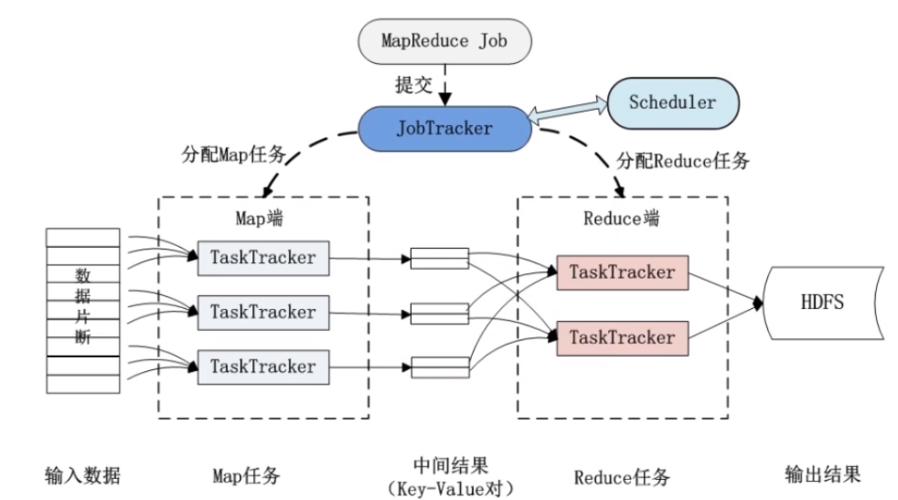

MapReduce框架的基本原理
MapReduce是面向大规模数据处理的分布式计算模型,它通过将任务分为两个阶段——Map和Reduce,实现了高效的数据处理,下面简要介绍其主要组件和流程:
1. Map阶段
功能: 数据的映射和过滤。
处理: 数据被分成小块,每块由一个Map函数处理。
输出: 生成键值对作为中间结果。
2. Reduce阶段
功能: 数据的归约。
处理: 相同键的值被组织到一起,由Reduce函数处理。
输出: 最终结果通常存储在分布式文件系统中。
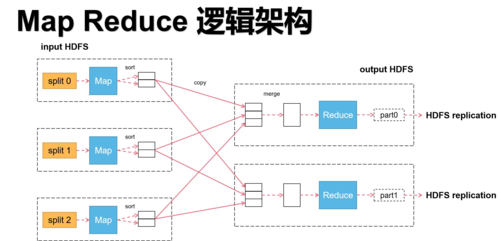
3. Shuffle机制
功能: 连接Map和Reduce阶段。
操作: 包括数据传输、排序和分发。
目的: 确保Reduce能接收到正确的数据。
4. 系统组件
MrAppMaster: 负责整个程序的过程调度及状态协调。
MapTask: 负责Map阶段的数据处理。
ReduceTask: 负责Reduce阶段的数据处理。
MapReduce应用开发常用概念
输入输出(InputFormat和OutputFormat)
InputFormat: 定义了数据的输入格式,包括如何将数据文件分割成可供Map任务处理的小块。
OutputFormat: 定义了输出数据的格式,以及如何写入到分布式文件系统中。
Hadoop Shell命令
提交作业: 用户可以通过Hadoop shell提交MapReduce作业。
管理作业: 包括杀死作业或执行其他HDFS文件系统操作。
为MapReduce框架及其开发中的核心概念,接下来是相关问题及解答环节:
问题与解答
Q1: MapReduce中的Shuffle机制是如何工作的?
A1: Shuffle过程主要包括三个步骤:Map任务完成后,其输出的键值对会被分成R个区域,这里的R是Reduce任务的数量;这些数据会根据分区信息传输到各个Reduce任务节点上;每个Reduce任务节点上的数据会被排序,确保同一key的值聚集在一起,以便进行后续的Reduce操作。
Q2: 在MapReduce中,如果某个Map任务失败会如何处理?
A2: MapReduce框架具有一定的容错机制,若Map任务失败,框架会自动重新执行失败的任务,这个过程通常在另一个集群节点上进行,并且只有失败的任务需要重做,其他已完成的任务不会受到影响,这确保了整个分布式计算过程的稳定性和可靠性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/579692.html
 微信扫一扫
微信扫一扫