

【MapReduce输出】
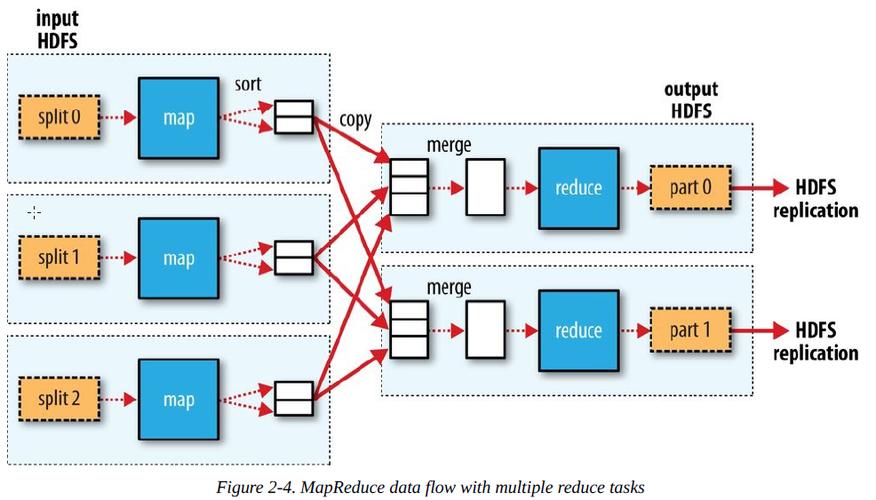

MapReduce是一种编程模型,用于处理和生成大数据集的并行计算,它由两个主要阶段组成:Map阶段和Reduce阶段,下面是一个详细的解释:
1、Map阶段:
输入数据被分割成多个独立的块(chunks)。
每个块独立地通过map函数进行处理。
map函数将输入数据转换为一组键值对(keyvalue pairs)。
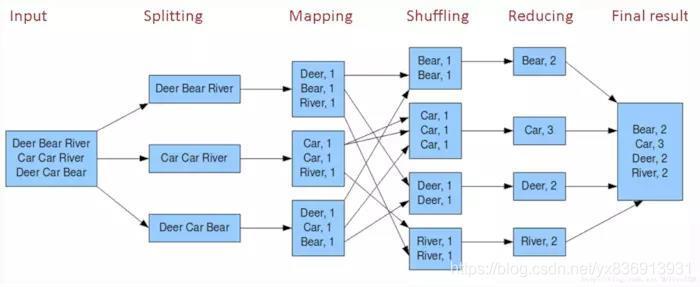
输出结果为中间键值对集合。
2、Reduce阶段:
所有具有相同键的键值对被分组在一起。
对于每个键,reduce函数接收一个键和一个值列表作为输入。
reduce函数对这些值进行某种聚合操作,例如求和、计数等。
最终输出结果为一组键值对,其中键是唯一的。
以下是一个简单的示例代码,演示了如何使用Python编写MapReduce程序:
from collections import defaultdict
import itertools
def map_function(data):
"""Map function to process input data and generate keyvalue pairs."""
result = []
for line in data:
words = line.split()
for word in words:
result.append((word, 1))
return result
def reduce_function(key, values):
"""Reduce function to aggregate values for each key."""
return (key, sum(values))
Example usage
input_data = ["hello world", "hello python", "world of maps"]
mapped_data = map_function(input_data)
grouped_data = defaultdict(list)
for key, value in mapped_data:
grouped_data[key].append(value)
reduced_data = [reduce_function(key, values) for key, values in grouped_data.items()]
print(reduced_data)
在这个示例中,我们首先定义了一个map_function来处理输入数据并生成键值对,我们使用defaultdict来收集相同键的值,最后应用reduce_function来计算每个键的总计数。
【相关问题与解答】
问题1:MapReduce如何确保在分布式环境中的数据一致性?
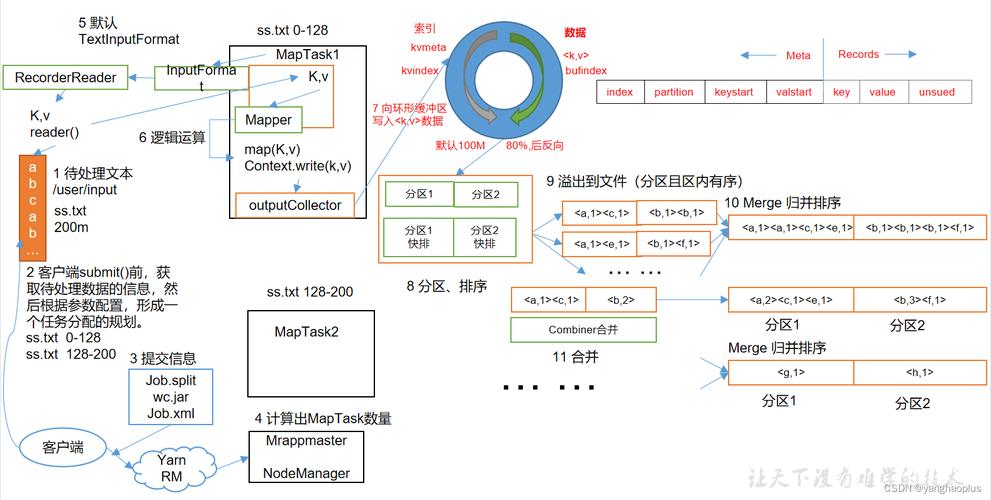
答案1:MapReduce框架通常使用一种称为"shuffle"的过程来确保数据一致性,在Map阶段结束后,中间键值对会被排序并分配给不同的Reduce任务,每个Reduce任务只处理其分配到的键值对,从而避免了不同任务之间的数据冲突,MapReduce还提供了容错机制,如备份和恢复机制,以确保数据的完整性。
问题2:MapReduce中的Map阶段和Reduce阶段是如何并行执行的?
答案2:MapReduce框架会自动将输入数据分割成多个块,并将这些块分配给集群中的不同节点上运行的Mapper任务,每个Mapper任务独立地对其分配的数据块执行Map函数,并生成中间键值对,这些中间键值对会被收集起来,并在Shuffle阶段根据键进行排序和分区,每个Reducer任务会处理分配给它的键值对,执行Reduce函数以生成最终的结果,整个过程中,Map阶段和Reduce阶段的执行是并行进行的,从而提高了处理大规模数据集的效率。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/579708.html
 微信扫一扫
微信扫一扫