

MapReduce详解
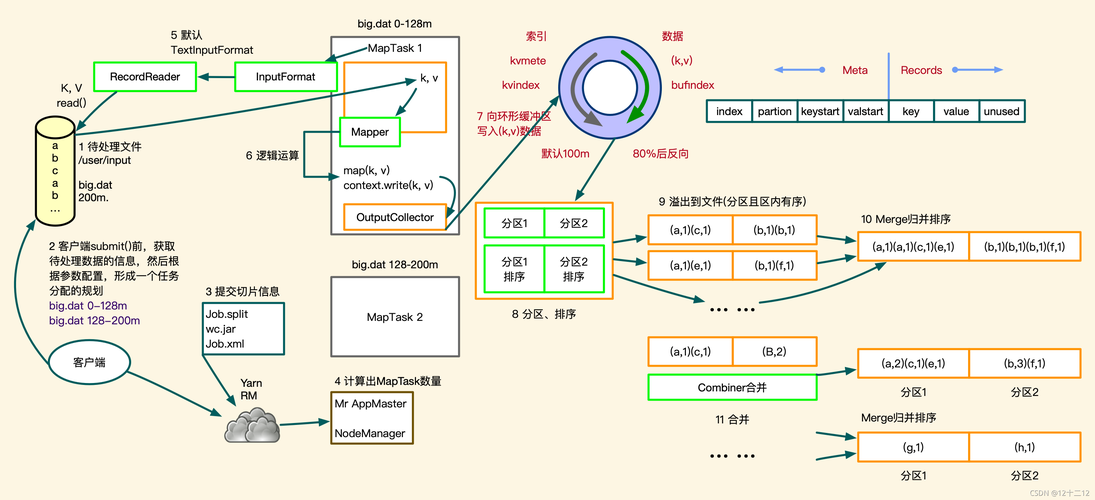

MapReduce是一种编程模型,用于处理和生成大数据集,该模型包括两个主要阶段:Map阶段和Reduce阶段,Map阶段对数据进行过滤和排序,而Reduce阶段则对所有相同的键进行聚合操作。
Map阶段
在Map阶段,输入数据被分割成多个数据块,每个数据块由一个Map任务进行处理,每个Map任务都会读取一个数据块,然后对其进行处理,生成一组中间键值对,这些中间键值对会被写到本地磁盘上,并按照键进行排序。
输入数据
Map阶段的输入数据通常是一个文件或多个文件的集合,这些文件会被分成多个数据块,每个数据块由一个Map任务进行处理。
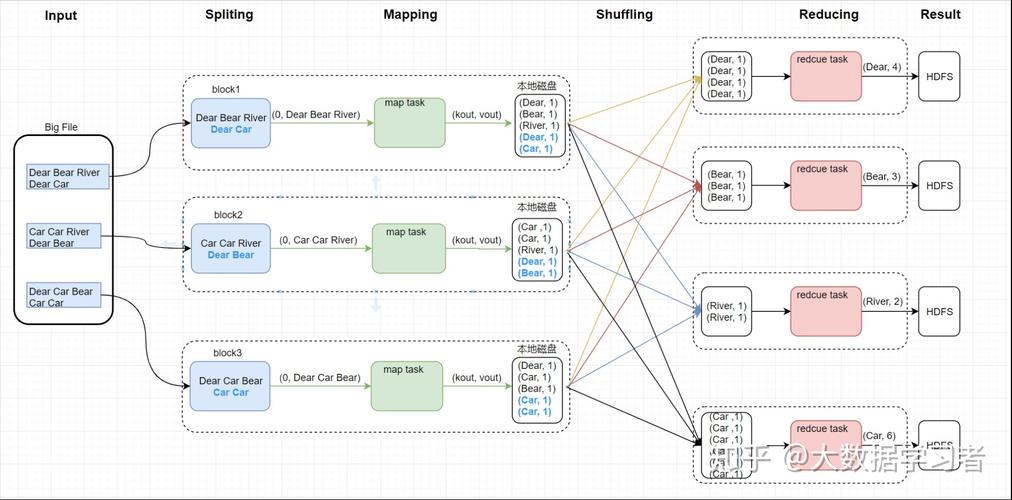
Map函数
Map函数接收一个键值对作为输入,然后对其进行处理,生成一组中间键值对,这些中间键值对会被写到本地磁盘上,并按照键进行排序。
输出数据
Map阶段的输出数据是一组中间键值对,这些键值对会被写到本地磁盘上,并按照键进行排序。
Reduce阶段
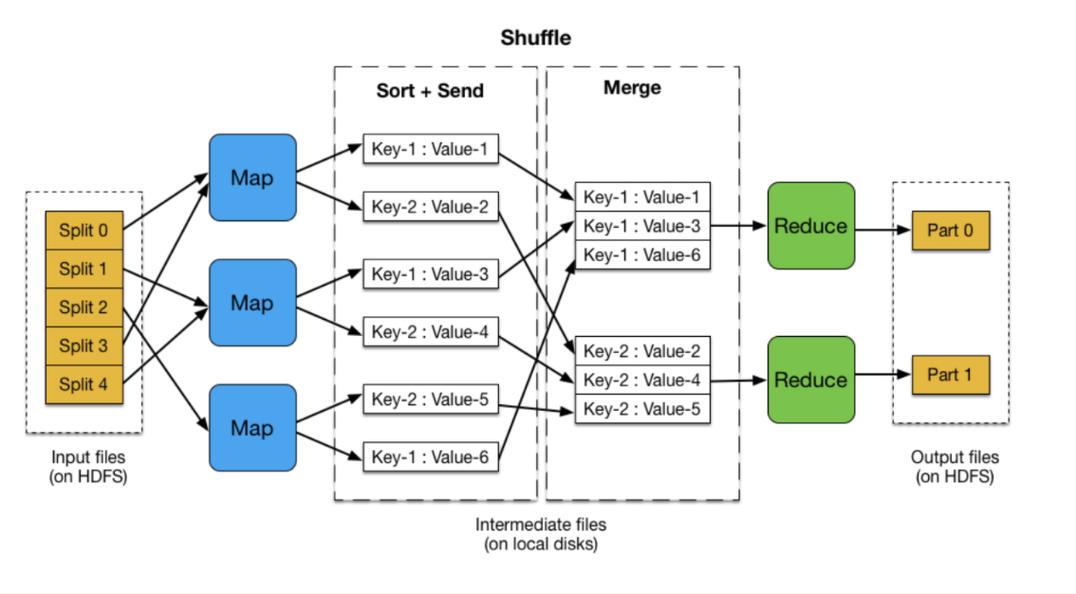
在Reduce阶段,所有的Map任务都已经完成,Reduce任务开始执行,每个Reduce任务都会读取所有Map任务的输出数据,然后对其进行处理,生成最终的结果。
输入数据
Reduce阶段的输入数据是所有Map任务的输出数据,这些数据会被按照键进行分组,每个组由一个Reduce任务进行处理。
Reduce函数
Reduce函数接收一个键和一个值列表作为输入,然后对其进行处理,生成最终的结果,这个结果会被写到HDFS(Hadoop Distributed File System)上。
输出数据
Reduce阶段的输出数据是最终的结果,这个结果会被写到HDFS上。
相关问题与解答
问题1:MapReduce如何处理大数据?
答:MapReduce通过将大数据分割成多个小数据块,然后并行处理这些数据块,从而有效地处理大数据,在Map阶段,每个Map任务都会读取一个数据块,然后对其进行处理,生成一组中间键值对,在Reduce阶段,每个Reduce任务都会读取所有Map任务的输出数据,然后对其进行处理,生成最终的结果。
问题2:MapReduce如何保证数据的完整性和一致性?
答:MapReduce通过使用分布式文件系统(如HDFS)来保证数据的完整性和一致性,在Map阶段,每个Map任务都会将其输出数据写到本地磁盘上,然后再将这些数据复制到其他节点上,在Reduce阶段,每个Reduce任务都会从所有Map任务的输出数据中读取数据,然后对其进行处理,这样,即使某个节点发生故障,也不会影响整个系统的运行。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/579728.html
 微信扫一扫
微信扫一扫