

MapReduce模型概览

基本概念与历史背景
MapReduce由函数式和矢量编程语言借鉴而来,主要通过“映射”(Map)和“化简”(Reduce)两个阶段处理数据。
起源于Google的论文《Simplified Data Processing on Large Clusters》,后成为Hadoop项目的核心组件,用于分布式计算。
核心原理解析
Map阶段与Reduce阶段
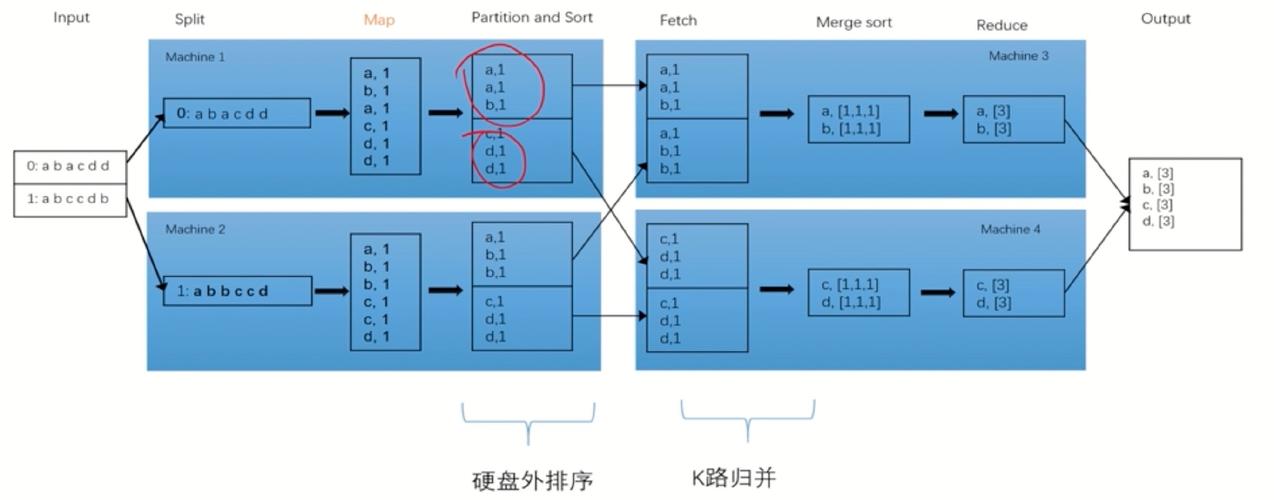
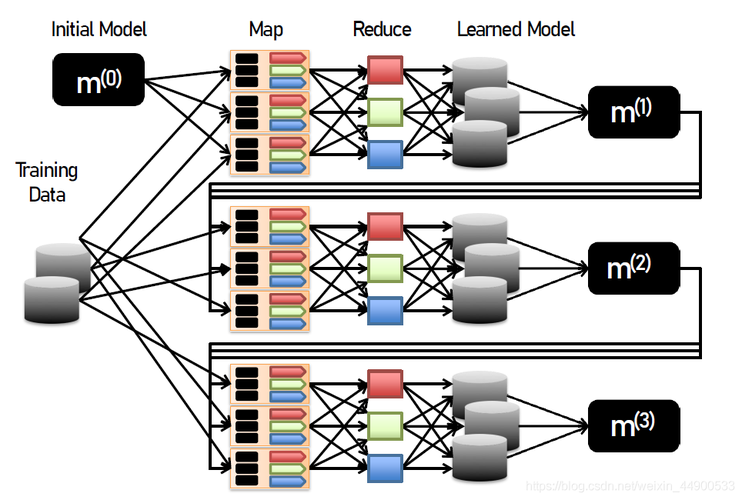
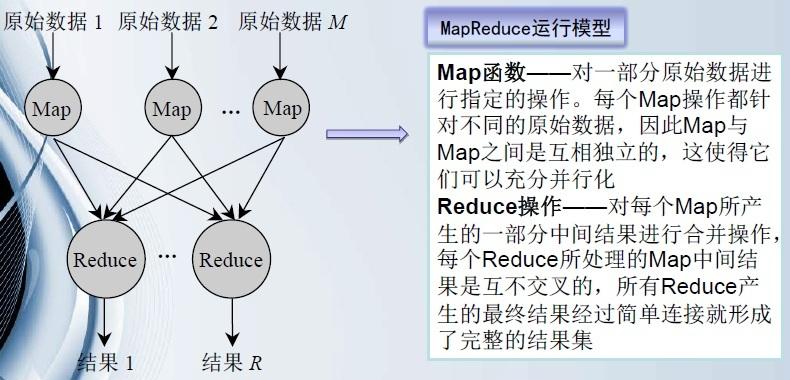
Map阶段:将输入数据切分为独立的数据块,由不同节点并行处理,生成键值对作为中间结果。
Reduce阶段:对Map阶段产生的中间结果按键进行汇总,合并相同键的值,输出最终结果。
系统架构与工作流程
Hadoop框架下的MapReduce包含一个作业追踪器和多个任务追踪器,负责任务分配、监控和错误恢复。
工作流程从作业提交到HDFS开始,经过分片、映射、排序、混洗、化简,最终写入HDFS。
应用场景与优势
大数据处理案例
常用于搜索引擎索引构建、日志分析、数据挖掘等场景,能够高效处理TB至PB级别的数据集。
优势在于高扩展性、高容错性和易于编程,使开发者能够轻松处理大规模数据集。
性能优化策略
提升数据处理效率
合理设置Map和Reduce任务数量,平衡负载,避免单个节点过载影响整体性能。
使用压缩技术减少数据传输量,提高网络传输效率,同时降低I/O开销。
相关问题与解答
问题1:MapReduce如何处理硬件故障?
答案:MapReduce设计了容错机制,包括重新执行失败的任务和备份数据的机制,确保在硬件故障时数据处理的正确性和完整性。
问题2:是否可以在非Hadoop环境下实现MapReduce?
答案:是的,MapReduce是一种编程模型,其核心思想可以在多种分布式环境中实现,不局限于Hadoop平台。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/579748.html
 微信扫一扫
微信扫一扫