

MapReduce中的max_MAX概念
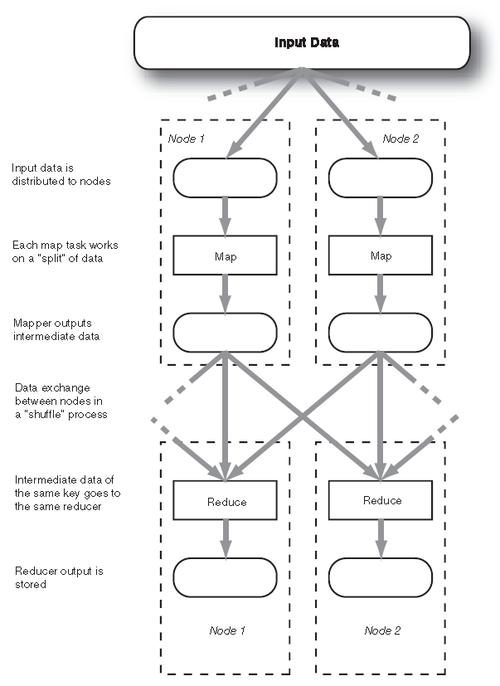

MapReduce 是一种编程模型,用于处理和生成大数据集,它包含两个主要阶段:Map 和 Reduce,在这两个阶段中,max_MAX 是一个关键的概念,特别是在处理数值型数据时,小编将详细解释max_MAX 的含义、应用以及如何在 MapReduce 程序中使用它。
Max_MAX 的定义
max_MAX 是在 MapReduce 框架中设置的一个配置参数,它用于控制 Reduce 阶段能够接收的最大键值对数量,这个参数对于优化性能和资源使用非常关键,尤其是在处理具有大量唯一键的数据时。
应用场景
大数据处理:在处理大规模数据集时,尤其是当键的数量非常多时,max_MAX 可以帮助限制单个 Reduce 任务的负载。
内存管理:通过调整max_MAX,可以更有效地管理内存资源,防止单个 Reduce 任务因为过多的数据而崩溃。
性能优化:适当的max_MAX 设置可以平衡各个 Reduce 任务的工作量,避免某些任务过重而延长整个作业的完成时间。
如何设置 Max_MAX
在不同的 Hadoop 版本和不同的 MapReduce 框架中,设置max_MAX 的方法可能有所不同,它需要在作业配置中进行设置,在 Hadoop 中,可以通过以下方式设置:
Job job = new Job(conf);
job.getConfiguration().set("mapreduce.job.reduces", "N"); // N 是 reduce 任务的数量
job.getConfiguration().set("mapreduce.reduce.max.total.groups", "M"); // M 是 max_MAX 的值
相关问题与解答
Q1: 如果设置了较小的 max_MAX 值会发生什么?
A1: 如果设置了较小的max_MAX 值,可能会导致每个 Reduce 任务处理的键值对数量减少,这可能会增加 Reduce 任务的数量,虽然这有助于平衡负载,但也可能导致更多的磁盘 I/O 操作和更复杂的任务管理,从而影响整体性能。
Q2: max_MAX 是否会影响 Map 阶段的输出?
A2:max_MAX 本身不会直接影响 Map 阶段的输出,因为它是 Reduce 阶段的一个配置参数,了解max_MAX 的设置对于设计 Map 函数的输出(特别是键的设计)是有帮助的,因为 Map 输出的键将会被分发到不同的 Reduce 任务中去处理,合理的max_MAX 设置可以帮助更好地设计 Map 函数,以适应后续的 Reduce 处理。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/579760.html
 微信扫一扫
微信扫一扫