

决策树回归与MapReduce结合
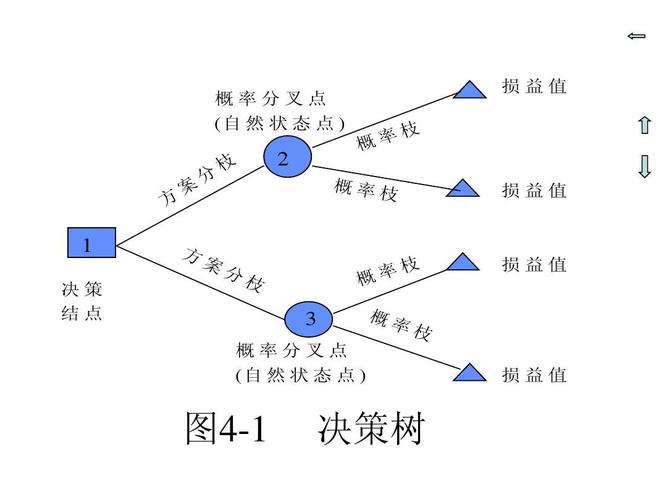

决策树回归作为一种监督学习算法,通过不断划分输入特征来建立决策逻辑,在大数据环境下,MapReduce编程模型能够有效地处理大规模数据集,提升决策树回归算法的运算效率和数据处理能力。
决策树基础
1、定义与目标:决策树是一种以树形结构来表示决策过程的算法,可用于解决分类和回归问题,它通过不断划分输入特征来建立一棵决策树,目标是最小化总体误差或最大化预测精度。
2、构建过程:构建决策树的过程通常从根节点开始,每次根据某一特征的最优切分将数据划分为不同的子集,递归此过程直到满足停止条件。
3、数学原理:决策树算法的核心在于选择合适的属性进行分割,这通常涉及到信息增益、基尼不纯度等指标的计算,以确定最佳的切分属性。
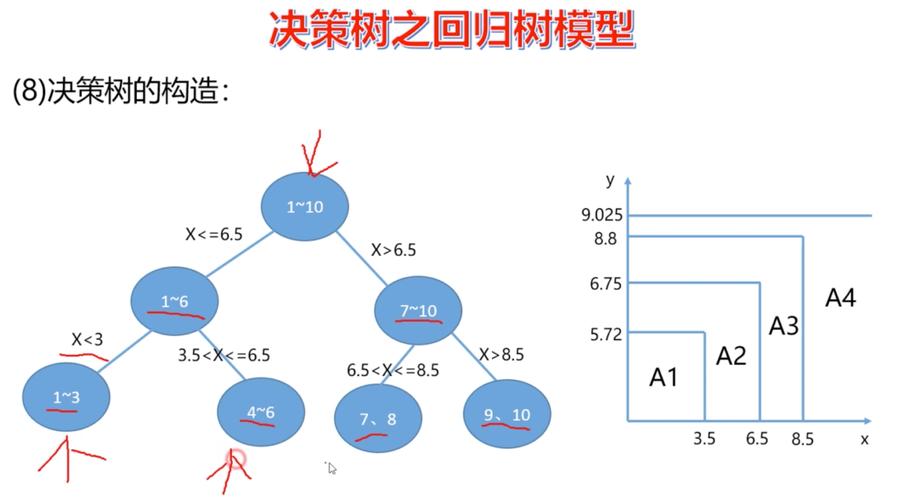
MapReduce在决策树中的应用
1、数据分布式处理:MapReduce通过将大规模数据集分布式处理,使得决策树回归算法能够有效地处理大数据,每个Map任务可以处理数据的一个子集,并生成局部决策树,之后通过Reduce任务合并成一个全局决策树。
2、优化算法效率:利用MapReduce并行处理的优势,可以显著提高决策树回归的训练速度和处理能力,特别是在面对海量数据时。
3、实现框架:在Apache Spark等大数据处理框架中,可以通过Spark SQL和MapReduce对决策树回归进行高效的实现和优化。
使用案例与实证分析
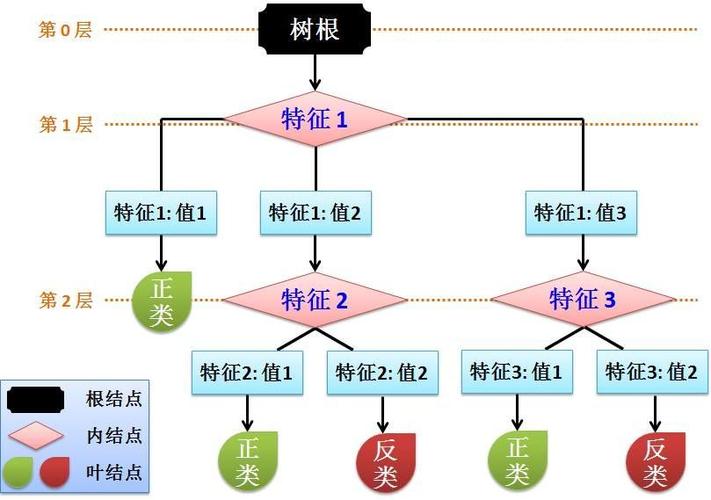
1、车祸影响因素分析:有研究使用决策树回归分析了影响车祸发生率的因素,如天气条件、道路方向等,这对于预防车祸和提高交通安全具有重要意义。
2、可视化分析:决策树的结果可以直观地展示在图表中,为决策者提供易于理解的决策依据,可以通过可视化工具展示不同因素对车祸发生率的影响。
在大数据时代,利用MapReduce等大数据处理技术,可以有效提升决策树回归算法的性能和准确性,使其更好地服务于数据分析和决策支持。
相关问题与解答
Q1: 决策树回归如何处理缺失值?
A1: 决策树回归处理缺失值的常见方法包括使用替代值(如均值、中位数)、基于概率分布填补、使用预测模型估计缺失值等,具体选择哪种方法取决于数据的特性和应用场景,在预处理阶段,也可以通过删除含有缺失值的记录或对缺失值进行特殊标记来处理。
Q2: 如何评估决策树回归模型的性能?
A2: 评估决策树回归模型性能的常用指标包括均方误差(MSE)、决定系数(R²)等,这些指标可以帮助我们了解模型在训练集和测试集上的表现,进而调整模型参数或结构以提高其泛化能力。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/579801.html
 微信扫一扫
微信扫一扫