

MapReduce面试题解析

MapReduce是一个分布式运算程序的编程框架,允许开发者在Hadoop集群上编写和运行数据处理任务,本文将详细解析MapReduce的面试题目,帮助应聘者更好地理解和准备面试。
MapReduce基础概念
MapReduce定义及核心思想
定义:MapReduce是一个用于大规模数据处理的编程模型,它将任务分为两个阶段——Map和Reduce。
核心思想:采用“分而治之”的策略,即先将大任务分解为多个小任务并行处理,然后再将结果合并。
MapReduce的工作原理
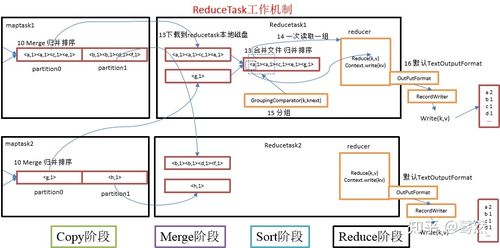
MapReduce作业执行流程包括输入分片、Map任务执行、Shuffle和Sort过程、以及Reduce任务执行,Shuffle是MapReduce的核心环节,负责将Map输出的数据传送给Reduce。
配置与优化
Map和Reduce的数量配置
Map数量:由切片信息决定,每个切片对应一个Map任务,切片的大小通常与HDFS的block大小相同,但不会跨越文件边界。
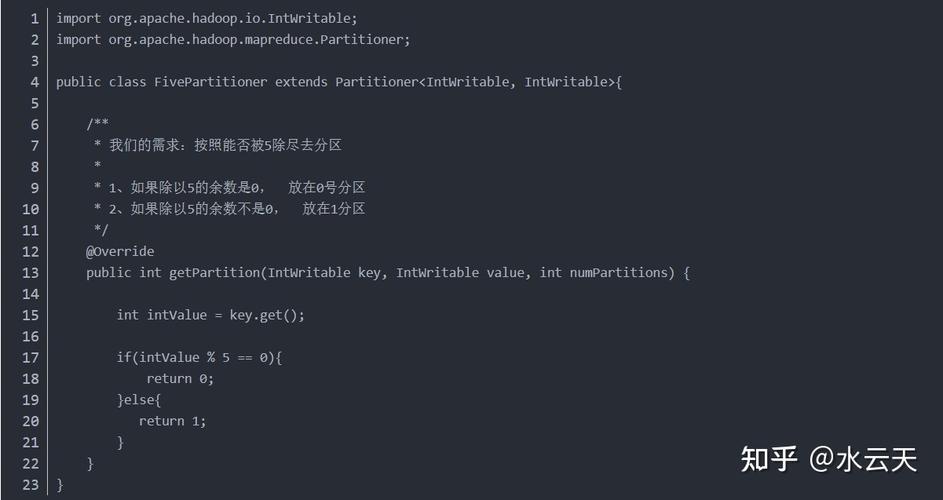
Reduce数量:可通过配置文件或代码进行设置,根据实际需求和集群资源调整。
MapReduce优化经验
合理设置Map和Reduce个数:平衡资源使用和减少任务执行时间。
避免数据倾斜:通过合理的Key设计避免某些Reduce处理过多数据。
使用Combine函数:在Map端进行局部聚合,减少数据传输量。
数据压缩:对输出数据进行压缩,节省存储空间和提高传输效率。
高级特性与问题分析
Shuffle和Sort机制
Shuffle过程:是将Map输出的数据分发到各个Reduce的过程,是MapReduce中最有挑战性的环节之一。
排序算法:Shuffle过程中通常包含排序,以确保数据按照Key有序,便于后续处理。
环形缓冲区的作用
减少磁盘I/O操作,提高数据处理效率。
防止数据在Map和Reduce之间传输时丢失。
相关问题与解答
Q1: 如何确定MapReduce作业中Map和Reduce的最佳数量?
A1: Map数量通常由输入数据的切片数决定,而Reduce的数量则根据作业的复杂度和集群的资源情况进行调整,可以通过实验和监控工具来找到最佳的配置。
Q2: 在MapReduce中,如果某个Reduce处理的数据量远远大于其他Reduce,该如何解决?
A2: 这种情况被称为数据倾斜,解决方法包括重新设计Key的分配策略,使用随机Key或者在Map阶段引入Combine函数来局部聚合数据,减少单个Reduce的负担。
通过上述解析,希望应聘者能够对MapReduce的关键概念和常见问题有更深入的理解,并在面试中表现出色。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/579833.html
 微信扫一扫
微信扫一扫 