

MapReduce视频教程

1、MapReduce简介
定义与重要性: MapReduce是一个分布式运算的编程框架,主要用于处理和生成大规模数据集,该模型在Hadoop中获得广泛应用,是大数据处理的核心技术之一。
历史背景: 最初由Google提出用于其搜索业务,之后被Apache Hadoop项目采纳并广泛推广。
2、核心概念解析
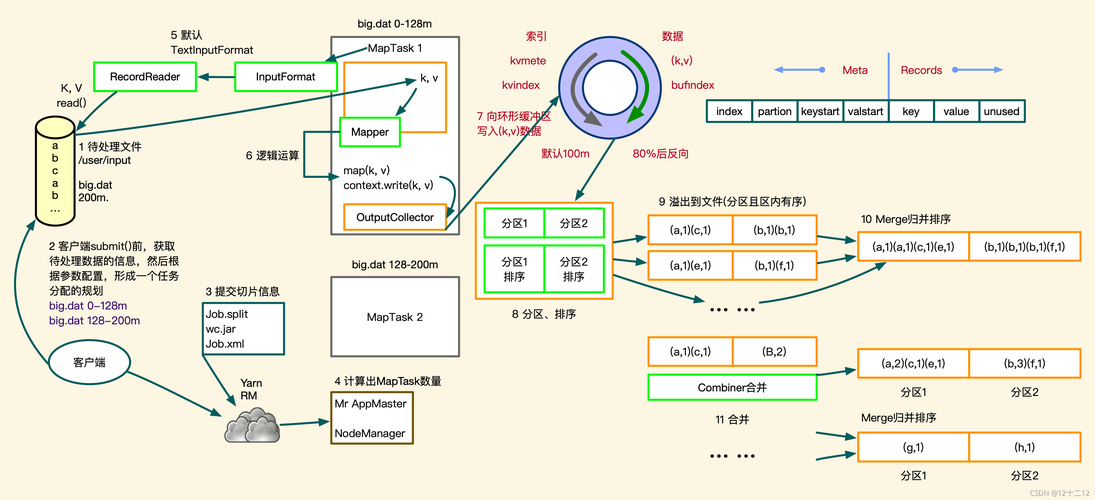
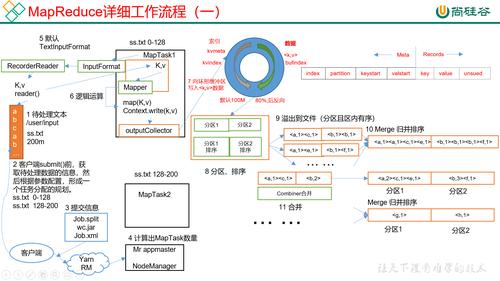
Map函数: 负责将输入数据映射到一组中间键值对,这个过程通过用户编写的Map函数完成,旨在处理数据并将其转换为适合后续归约操作的格式。
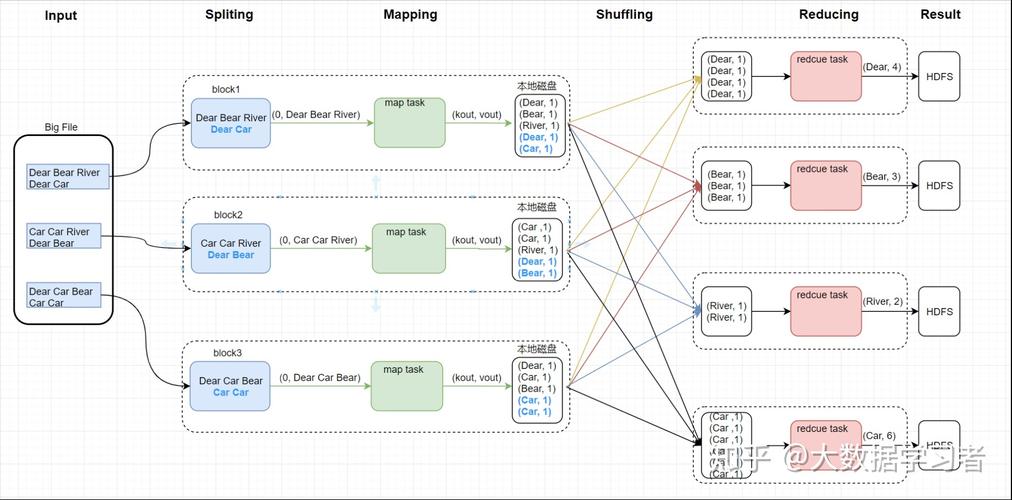
Reduce函数: 所有具有相同键的值被整合在一起,用户定义的Reduce函数作用于这些值,以获得最终结果。
3、编程规范和模式
数据流: MapReduce作业通常从HDFS读取数据,并在处理后写回HDFS,理解这一流程有助于设计更高效的数据处理任务。
容错机制: 由于硬件故障是常态,因此MapReduce提供了容错机制,确保作业可以在出现故障的情况下顺利完成。
4、环境搭建和配置
安装Hadoop: 详细步骤包括下载Hadoop二进制文件,配置环境变量,设置Hadoop集群等。
配置MapReduce: 包括设置MapReduce作业的内存、运行时间等参数,以及如何提交和监控作业。
5、实际应用案例
商业智能分析: 使用MapReduce进行日志分析,帮助公司了解用户行为,从而制定更有效的市场策略。
实时数据处理: 虽然MapReduce设计为批处理,但结合其他技术如Apache Flume或Kafka可以实现近实时数据处理。
6、问题排查与性能优化
常见问题: 如数据倾斜、作业失败重启等,提供问题诊断和解决策略。
优化技巧: 包括合理设置数据块大小、合理配置Map和Reduce数量等。
相关问题与解答
1、如何使用MapReduce处理图像数据?
可以使用MapReduce进行图像数据的处理,例如图像特征提取,在Map阶段,每个Map任务可以处理一部分图像集,从中提取特定特征;在Reduce阶段,则可以对这些特征进行汇总或进一步的分析。
2、MapReduce在非Hadoop环境中如何工作?
MapReduce的设计原理允许它在任何支持分布式计算的环境中工作,虽然它常与Hadoop一起使用,但也可以在Apache Spark或其他分布式系统中实现类似的功能,在这种环境下,需要相应地调整部署和配置策略。
MapReduce作为一个强大的分布式处理框架,不仅适用于大数据处理,还可以灵活应用于多种数据处理场景,希望通过本教程的介绍,能够帮助您更好地理解和应用MapReduce技术。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/579953.html
 微信扫一扫
微信扫一扫