

MapReduce对Hive操作深入解析

与核心组件
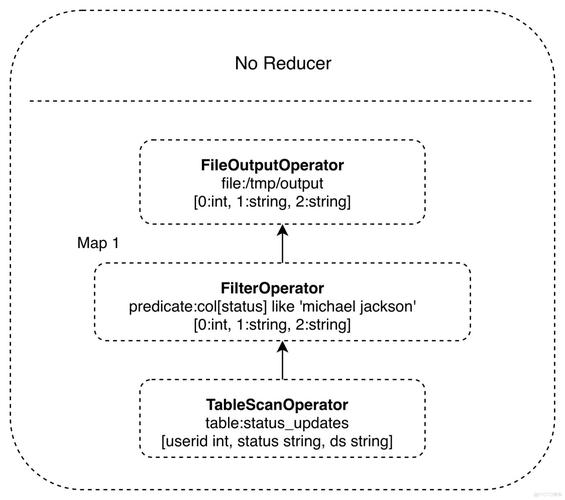
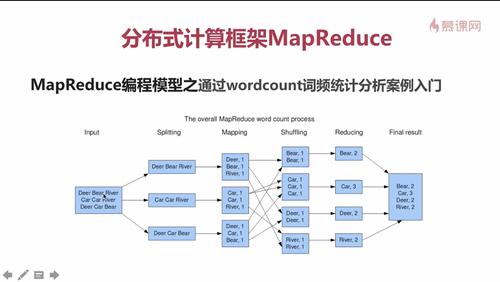
MapReduce框架:MapReduce是大规模数据处理的编程模型,通过将计算任务分发到多个节点并行处理,提高处理速度,该框架分为两个阶段:Map阶段和Reduce阶段,在Map阶段,系统先对数据进行分割,然后各个节点处理分派给自己的数据;Reduce阶段则将Map阶段的输出进行处理,得到最终结果。
Hive数据仓库:Hive是一个建立在Hadoop之上的数据仓库工具,可以将SQL查询转换为MapReduce作业,这样用户可以使用熟悉的SQL语法进行大规模数据查询,而背后的复杂MapReduce操作则由Hive自动处理。
Hadoop高可用性:为保证数据处理的稳定性和可靠性,Hadoop设计了高可用性(HA)特性,这意味着在出现硬件故障或网络问题时,系统能够快速恢复,继续数据处理任务,从而避免长时间停机带来的损失。
Hive与MapReduce交互机制
SQL到MapReduce的转换:当用户在Hive中执行一个SQL查询时,Hive会将这个查询转换成一个或多个MapReduce作业,这一过程包括语法解析、查询优化等步骤,确保转换后的作业能够高效执行。
执行MapReduce作业:转换得到的MapReduce作业将提交给Hadoop集群执行,在执行过程中,Hadoop框架会自动处理数据分发、任务调度等问题,用户无需关心这些底层细节。
Hive中的Join操作
Map Join:当进行表连接操作时,如果其中一个表较小,可以采用Map Join方式,这种操作会将小表分发到所有节点并在内存中进行缓存,使得每个节点可以独立完成连接操作,从而提高处理速度。
Reduce Join:对于大表的连接操作,通常使用Reduce Join,此方式会将所有的连接操作集中在Reduce阶段完成,这有助于处理大数据量级的连接操作,但可能影响性能。
MapReduce的高级应用
Tez计算框架:Tez是Apache推出的支持有向无环图(DAG)的计算框架,与传统MapReduce相比,Tez能进一步细分Map和Reduce的操作,提供更灵活的数据流和控制流,以优化复杂的数据处理任务。
Shuffle和Sort:在MapReduce中,Shuffle和Sort阶段是连接Map和Reduce之间的桥梁,这个阶段负责将Map阶段的输出传输并排序,以便Reduce阶段可以正确地汇总数据。
常见问题解答
Q1: Hive是否可以处理所有SQL操作转化为MapReduce?
A1: 虽然Hive能处理大部分SQL操作,但对于一些特别复杂的查询或特定的数据库函数,Hive可能无法有效地转换为MapReduce作业,或者转换效率不高。
Q2: 如何优化Hive查询的性能?
A2: 可以通过分区、索引、选择合适的文件格式等方法来优化Hive的性能,合理调整MapReduce作业的配置参数,如内存大小、并发任务数等,也能显著提升性能。
通过上述的深入分析,可以看出MapReduce与Hive的紧密配合极大地简化了大数据处理的复杂性,了解其内部机制和优化方法,可以帮助用户更高效地利用这些工具进行数据处理和分析。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/579993.html
 微信扫一扫
微信扫一扫