

MapReduce是一个高效的分布式计算模型,用于处理大规模数据集,小编将详细介绍MapReduce的关键概念及其在应用开发中的使用。
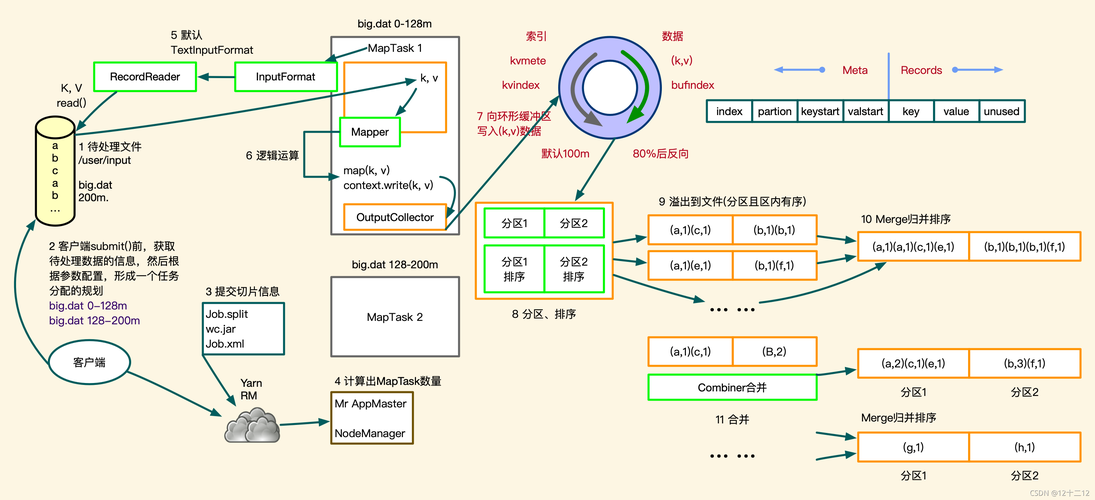

MapReduce核心概念
1.Map阶段
定义与功能:Map阶段的主要任务是将输入数据拆分成独立的数据块,并通过用户定义的Map函数处理这些数据块,生成一组中间键值对。
输出特点:Map函数的输出是一系列键值对,这些键值对后续会经过排序和分组。
2.Shuffle阶段
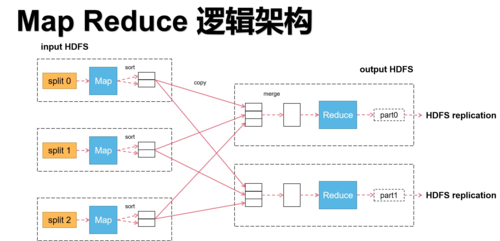
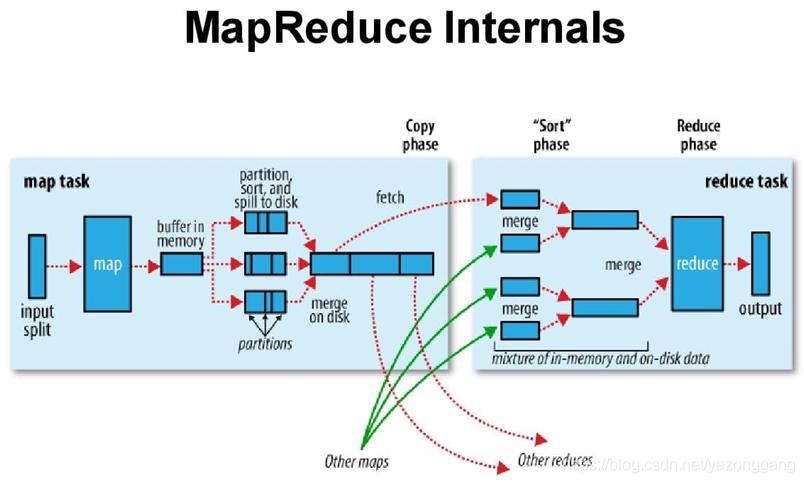
作用:Shuffle阶段是连接Map和Reduce的桥梁,主要负责对Map输出的键值对进行排序和传输。
详细过程:在此阶段,系统会将Map的输出根据键进行排序,然后将具有相同键的值聚集在一起,最后将这些键值对分发到各个Reducer。
3.Reduce阶段
核心操作:Reduce阶段接收来自Shuffle的键和对应的值集合,然后通过用户定义的Reduce函数处理这些数据,通常用来进行数据的汇总或聚合操作。
输出结果:Reduce阶段的输出是最终的处理结果,通常会被存储到文件系统。
MapReduce的应用开发
1.环境配置
Hadoop集群设置:首先需要配置Hadoop集群,包括设置硬件资源、网络和Hadoop相关软件。
开发环境准备:安装并配置必要的开发工具,如Java、Eclipse等,以及相关的库和API。
2.编程实践
编写Map和Reduce函数:开发者需要根据具体的业务需求编写Map和Reduce函数,这是实现分布式计算的核心。
数据输入输出处理:设定数据的输入格式和输出路径,确保程序可以正确读写数据。
3.性能优化
并行处理:合理设置Map和Reduce任务的数量,以充分利用集群的计算资源。
内存管理:优化数据处理逻辑,防止内存溢出等问题,提高程序的稳定性和效率。
关于MapReduce的相关问题与解答
问题1: MapReduce如何处理数据倾斜问题?
答案: 数据倾斜是指MapReduce作业中某些节点处理的数据量远大于其他节点,导致整体处理速度变慢,解决这一问题的常用方法包括提前对数据进行采样分析,适当调整分区函数使数据分布更均匀,或者使用MapJoin等技术减少数据传输。
问题2: 如何选择合适的Map和Reduce任务数量?
答案: 选择Map和Reduce任务的数量依赖于具体数据集的大小和集群的配置,一般建议Map任务的数量接近于数据分片的数量,而Reduce任务的数量则可以根据实际的硬件资源和预期的并发量来决定,通常情况下,设置510个Reduce任务可以较好地平衡负载。
通过上述深入介绍,可以看出MapReduce不仅适用于大数据处理,也提供了多方面的优化空间,正确地利用这些技术,可以显著提高数据处理的效率和效果。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/580093.html
 微信扫一扫
微信扫一扫