

YARN(Yet Another Resource Negotiator)和MapReduce是Hadoop框架中两个重要的概念,它们在基本概念、系统架构和容错性等方面有所不同,具体分析如下:

1、基本概念
MapReduce:是一种编程模型,用于大规模数据集的并行处理,它主要包括两个阶段:Map阶段和Reduce阶段。
YARN:是一个集群资源管理系统,负责资源管理和作业调度,它使Hadoop能够更高效地利用集群资源,支持更多类型的应用程序,不仅限于MapReduce作业。
2、系统架构
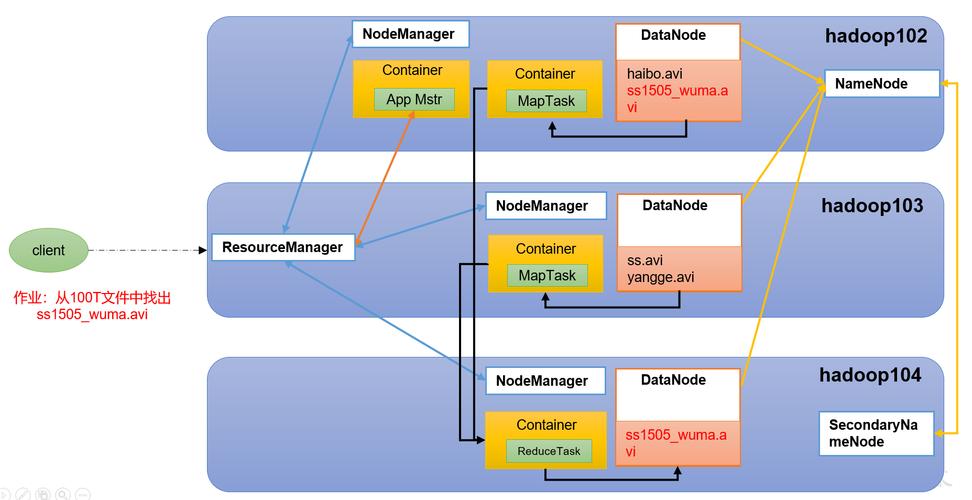
MapReduce:由JobTracker和TaskTracker组成,JobTracker负责作业调度和监控,而TaskTracker在各个节点上负责任务执行。
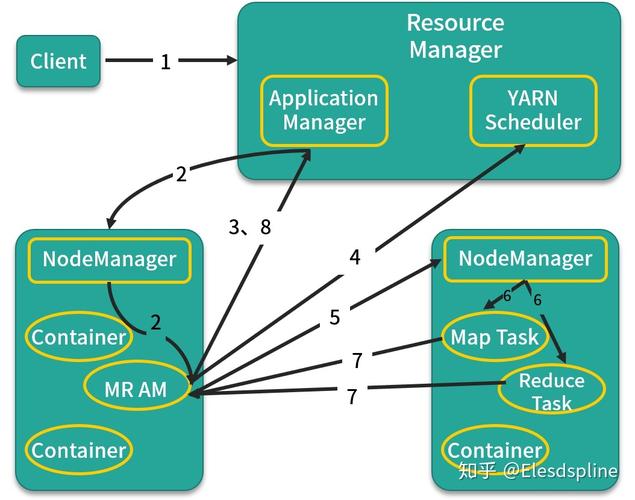
YARN:包括Resource Manager、Node Manager和Application Master,Resource Manager负责全局资源分配,Node Manager运行在每个节点上负责资源和任务管理,Application Master负责协调运行在YARN上的应用程序。
3、容错性
MapReduce:JobTracker是单点故障的瓶颈,一旦JobTracker出现问题,整个系统可能会受到影响。
YARN:由于Resource Manager和Application Master的职责分离,YARN提供了更好的容错性。
4、扩展性
MapReduce:存在可扩展性瓶颈,特别是在大量节点和任务的场景下,因为JobTracker需要管理所有作业和任务。
YARN:通过分离资源管理和任务调度,显著提高了系统的扩展性和灵活性。
5、资源利用率
MapReduce:只能运行MapReduce作业,资源利用率相对较低。
YARN:可以运行多种类型的应用程序,如Spark、Storm等,资源利用率更高。
6、作业运行
MapReduce:所有任务均由MapReduce框架管理。
YARN:可以为不同的应用程序提供定制化的运行时环境。
7、适用场景
MapReduce:适用于批量数据处理。
YARN:除了支持批量数据处理,还支持实时处理、交互式查询等多种场景。
8、性能优化
MapReduce:性能优化主要依赖于MapReduce程序的优化。
YARN:可以通过优化资源分配和任务调度来提升性能。
YARN作为Hadoop生态系统中的资源管理器,相较于传统的MapReduce框架,提供了更加灵活、高效的资源管理和作业调度能力,它通过分离资源管理和应用逻辑,不仅解决了MapReduce在扩展性和容错性方面的局限,还提升了集群的整体资源利用率和灵活性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/580117.html
 微信扫一扫
微信扫一扫