

MapReduce朴素贝叶斯 | 朴素贝叶斯分类
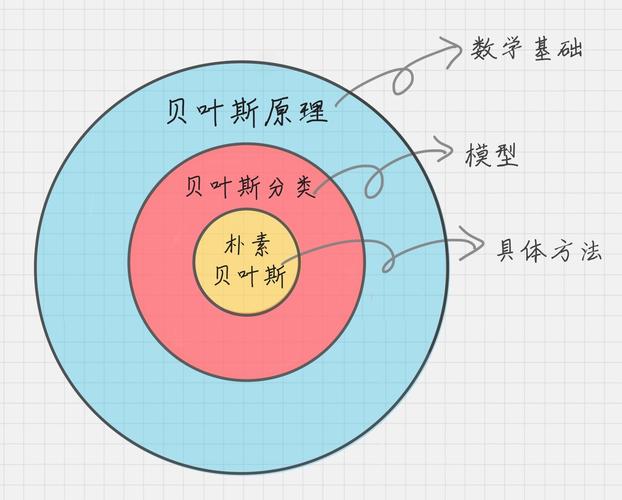

朴素贝叶斯分类器是一种基于贝叶斯定理的分类算法,以其简单高效和易于理解的特性在数据挖掘和机器学习领域得到了广泛应用,本文将探讨如何在Hadoop环境下,通过MapReduce编程模型实现朴素贝叶斯分类器。
一、理论基础
1. 贝叶斯定理
贝叶斯定理描述在给定某事件条件下另一事件发生的概率,数学表达式为:P(A|B) = P(B|A) * P(A) / P(B),其中P(A|B)是在已知B发生的条件下A发生的概率。
2. 朴素贝叶斯分类器
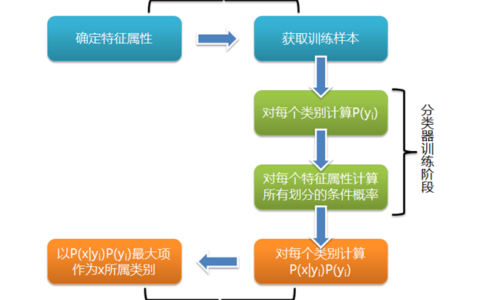
朴素贝叶斯分类器假设各特征之间相互独立,尽管这一假设在实际应用中往往过于简化,但它使得算法的计算复杂度大大降低,尤其适用于大规模数据集。
二、MapReduce编程模型
MapReduce是处理大规模数据集的编程模型,包括两个主要阶段:Map阶段和Reduce阶段。
1. Map阶段
在Map阶段,系统将输入数据分割成多个小数据块,然后并行处理这些数据块,生成键值对。
2. Reduce阶段
Reduce阶段负责接收来自Map阶段的输出,并根据键进行聚合,最终输出结果。
三、朴素贝叶斯与MapReduce
结合朴素贝叶斯和MapReduce,可以有效处理大规模数据集上的分类问题。
1. 数据准备
输入数据通常包含若干个特征和一个类别标签,天气数据集中可能包含天气状况、温度等特征以及是否适合进行某项活动的标签。
2. Map阶段设计
在Map阶段,每个Mapper会读取数据的一部分,并计算每个类别的先验概率以及每个特征在各类别下的条件概率。
3. Reduce阶段设计
Reduce阶段汇总来自所有Mapper的统计结果,完成最终的概率计算,并根据这些概率对新的实例进行分类预测。
四、优化与实现
1. 版本选择
根据实际需求,可以选择不同的编程语言实现,如Python、Java等。
2. 性能优化
在处理极大规模数据集时,需要考虑优化数据存储格式、减少网络传输量等策略以提高性能。
五、应用场景
朴素贝叶斯分类器因其简单和高效,常用于文本分类、垃圾邮件检测等领域。
六、常见问题解答
Q1: 朴素贝叶斯分类器的独立性假设会对结果产生哪些影响?
答案: 独立性假设虽简化了计算,但可能会忽略特征之间的关联,导致在某些情况下分类准确性降低。
Q2: 如何评估朴素贝叶斯分类器的性能?
答案: 通常使用准确率、召回率、F1分数等指标,通过交叉验证或在一个独立的测试集上进行评估。
朴素贝叶斯分类器结合MapReduce编程模型,为处理大规模数据集提供了一种高效的解决方案,通过优化和适当的特征工程,可以在多种应用场景下获得良好的分类效果。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/580125.html
 微信扫一扫
微信扫一扫