

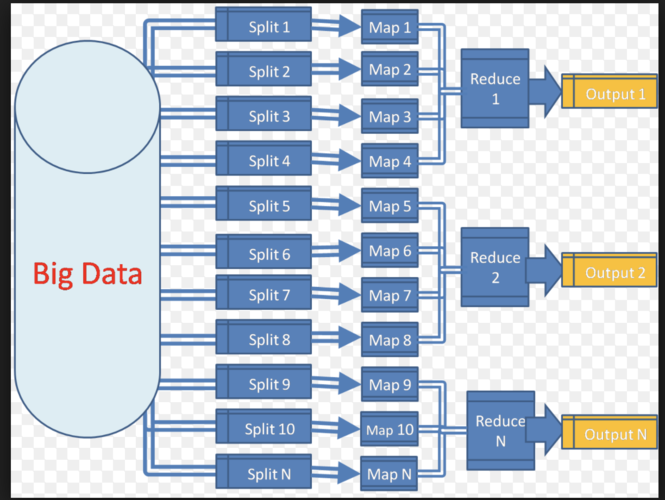
MapReduce 的 Partitioning
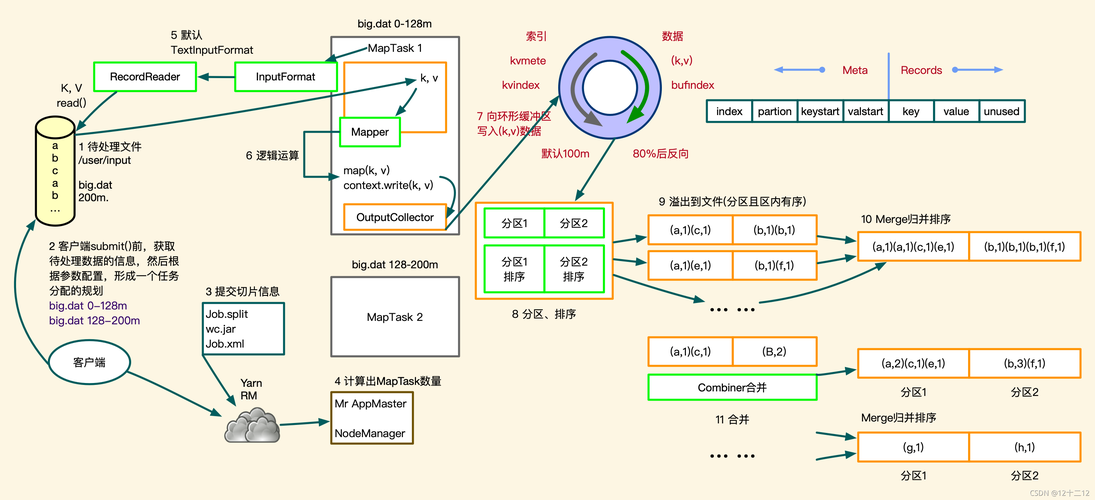

在 MapReduce 框架中,分区(Partitioning)是一个关键步骤,它负责将来自不同 Mapper 的输出数据分发到正确的 Reducer,分区的目的是确保具有相同键的所有数据项最终都由同一个 Reducer 处理,以下是分区过程的详细描述:
分区函数(Partition Function)
分区函数通常由用户实现。
它接收一个键和一个值,并返回该键应该去往的分区号。
Hadoop 默认的分区函数是hashPartition,它使用哈希函数对键进行分区。
示例代码:
int getPartition(KEY key, VALUE value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
数据流
Mapper 输出的数据首先被排序和分组,以便所有相同的键都在一起。
分区函数根据键决定每条记录应该发送到哪个 Reducer。
每个 Reducer 都会收到一组唯一的键及其对应的所有值。
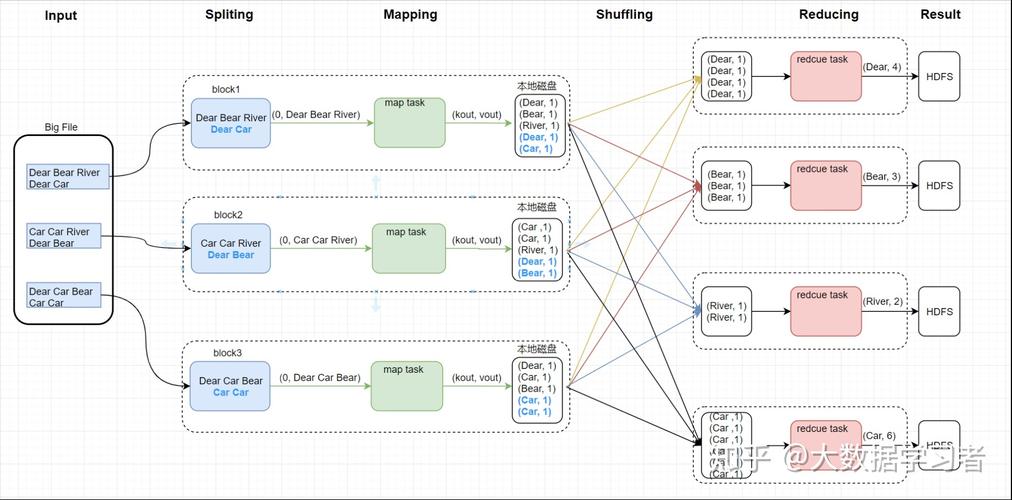
自定义分区
如果需要,用户可以编写自定义分区函数来控制数据如何分配到不同的 Reducer。
这在处理数据倾斜或优化特定类型的数据处理时非常有用。
示例场景:
假设你正在处理地理数据,你可能希望根据地理位置将数据分区,以便每个 Reducer 处理一个特定的地区。
相关问题与解答
问题 1: MapReduce 中的分区是如何帮助处理大规模数据集的?
解答: 在 MapReduce 中,分区确保了具有相同键的所有数据项都被发送到同一个 Reducer,这对于处理大规模数据集至关重要,因为:
它允许系统并行处理数据,每个 Reducer 独立工作在不同的数据集上。
它减少了数据传输量,因为只有具有相同键的数据才需要被传输到同一个 Reducer。
它简化了编程模型,因为开发者只需关注如何实现映射和归约逻辑,而不必担心数据的分布和聚合。
问题 2: 如何为 MapReduce 作业选择合适数量的 Reducer?
解答: 选择合适数量的 Reducer 取决于多个因素:
输入数据的大小和分布:如果数据倾斜严重,可能需要更多的 Reducer 来平衡负载。
资源限制:每个 Reducer 都需要一定的内存和CPU资源,因此需要根据集群的资源情况来决定。
作业的复杂性:更复杂的归约逻辑可能需要更多的时间,因此可能需要减少 Reducer 的数量以避免成为瓶颈。
I/O 和网络带宽:更多的 Reducer 意味着更多的输出文件,这可能会增加磁盘 I/O 和网络传输的开销。
通过实验和调整来找到最佳数量的 Reducer 是一个迭代的过程,Hadoop 允许用户在作业配置中设置 Reducer 的数量,以适应不同的作业需求。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/580213.html
 微信扫一扫
微信扫一扫