

在大数据开发中,获取并管理第三方jar包是开发者常见的需求之一,特别是在使用Spark等大数据处理框架时,正确配置和使用相关的库和依赖是非常重要的,小编将详细介绍如何获取Spark的Jar包,并解答相关的疑问。
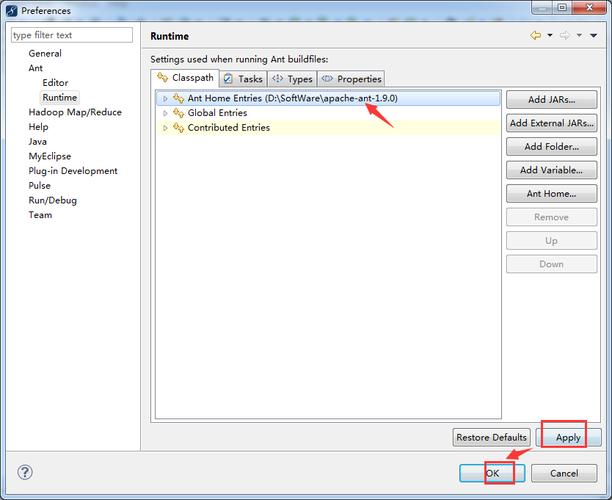

获取Spark Jar包的方法
1、通过开源镜像站获取
访问华为开源镜像站:可以直接访问华为开源镜像站(https://mirrors.huaweicloud.com/ )来下载需要的Spark Jar包,这个镜像站包含了各种常用的开源软件及其依赖,更新速度相对较快,是一个可靠的资源获取点。
选择合适的版本下载:在镜像站中,可以找到不同版本的Spark,选择与你的开发环境相匹配的版本进行下载,注意核对版本号以确保兼容性。
2、通过Maven管理
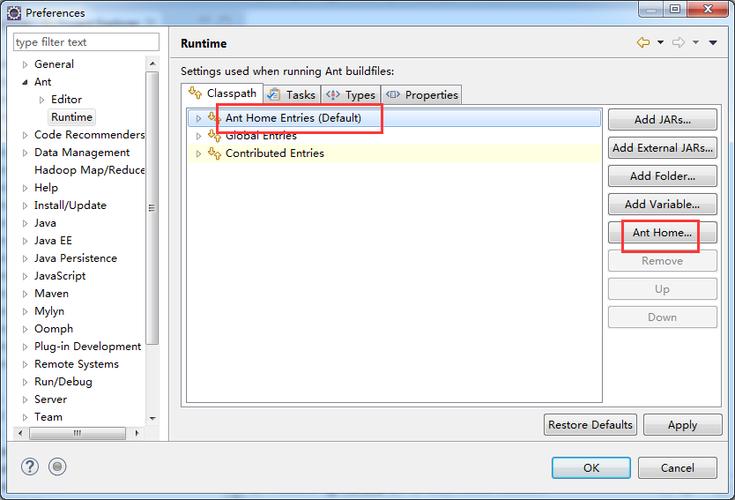
使用Maven仓库:对于使用Maven作为项目管理工具的开发者,可以直接在项目的pom.xml文件中添加Spark的依赖,Maven会自动从中央仓库或其他配置的仓库下载所需的jar包。
配置Maven的settings.xml:可能需要在Maven的settings.xml文件中添加华为云仓库或其他包含Spark jar包的仓库地址,以便Maven能够找到并下载这些依赖。
3、手动管理Jar包
下载后手动复制:如果无法通过自动化工具管理依赖,或者需要在一个没有网络连接的环境中使用Spark,可以选择手动下载Jar包,然后将其复制到相应的lib目录中(如$HADOOP_HOME/lib)以满足依赖需求。
更新和维护:手动管理Jar包需要注意定期检查更新,确保使用的是最新且稳定的库版本,以避免潜在的兼容性问题和安全风险。
表格归纳:获取Spark Jar包的方式
| 方式 | 途径 | 优点 | 缺点 |
| 开源镜像站 | 华为开源镜像站等 | 快速,适合批量下载多个版本 | 需要手动下载和管理 |
| Maven管理 | 自动从Maven仓库下载 | 便捷,自动处理依赖关系 | 需要正确的仓库配置 |
| 手动管理 | 下载后手动复制到lib目录 | 适用于无网络环境,完全控制版本 | 更新麻烦,容易出错 |
相关问题与解答
1、问:如果Maven仓库中找不到Spark的某个特定版本怎么办?
答:如果Maven仓库中找不到所需的Spark版本,可以尝试添加其他公共仓库(如华为云仓库)到Maven的settings.xml文件中,还可以直接从官方网站或其他可靠源手动下载Jar包,并本地安装到你的项目中。
2、问:手动管理Jar包时如何避免版本冲突?
答:手动管理Jar包时,建议维护一个清晰的文档记录每个Jar包的用途和版本号,在添加新依赖前确认其与现有依赖的兼容性,定期进行依赖升级和测试,以确保系统的稳定性和安全性。
应有助于理解如何有效地获取和管理Spark的Jar包,无论是通过开源镜像站直接下载、使用Maven自动管理还是手动复制文件,每种方法都有其适用场景和注意事项。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/580249.html
 微信扫一扫
微信扫一扫