

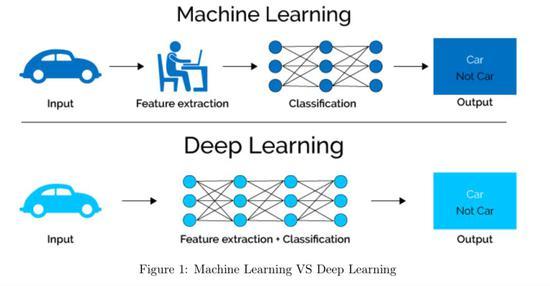
mean shift 机器学习_机器学习端到端场景

Mean Shift算法概念及应用
基本概念
Mean Shift,即均值漂移算法,最早由Fukunage在1975年提出,并由Yizong Cheng进一步发展,该算法通过迭代寻找数据密度的最大值,以达到聚类或模式识别的目的。
关键操作
算法的核心在于计算感兴趣区域内的数据密度变化,并据此移动中心点至密度最大处,此过程不断重复,直至中心点稳定。
应用领域
图像处理:平滑处理和图像分割是Mean Shift算法在图像处理中的两大主要应用,图像平滑通过压缩高质量图像的像素实现,而图像分割则是将图像分成多个部分,以便进一步分析。
物体跟踪:利用Mean Shift可以有效进行物体跟踪,通过识别连续帧中的目标位置,实现实时动态追踪。
机器学习端到端场景解析
初始阶段:问题定义与数据获取
问题定义:明确机器学习项目的目标和预期成果。
数据获取:收集、整理和标注必要的训练数据。
数据处理与模型训练
数据预处理:包括数据清洗、标准化等步骤,以提升数据质量。
模型选择与训练:根据问题类型选择合适的模型并进行训练。
模型评估与部署
模型评估:通过测试集评估模型性能,确保达到预定目标。
部署实施:将训练好的模型部署到生产环境,进行实际应用。
持续迭代与优化
反馈收集:收集用户反馈及模型在实际环境中的表现数据。
模型迭代:根据反馈对模型进行调整和优化。
相关问题与解答
Mean Shift算法的优缺点是什么?
优点:无需预设聚类数量,能够自适应地发现数据集中的模态;对数据分布的形状没有严格要求,适合不同类型的数据分布。
缺点:计算复杂度高,特别是在大规模数据集上运行时;对参数设置敏感,不同的带宽选择可能导致截然不同的结果。
如何选择合适的机器学习模型?
问题类型:根据问题是分类、回归还是聚类等,选择最符合任务需求的模型。
数据特性:考虑数据的维度、大小以及是否有时间序列等因素。
性能需求:根据实际应用场景对模型的精度、速度和资源消耗等进行权衡。
结合Mean Shift算法的特点与机器学习项目的一般流程,可以看出Mean Shift在特定领域如图像处理中具有显著优势,但需注意其在大规模数据处理时可能面临的效率问题,在选择机器学习模型时,应全面考虑问题类型、数据特性和性能需求,以确保最终的项目实施既高效又有效,希望本文能为您理解Mean Shift算法及其在机器学习端到端场景中的应用提供有价值的参考。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/580743.html
 微信扫一扫
微信扫一扫