

在大数据技术领域,MongoDB和Hadoop各自扮演着重要的角色,它们虽然都服务于大规模数据集的处理,但具有不同的特性和优势,以下将深入探讨MongoDB和Hadoop,并详细了解SQL on Hadoop的概念及其应用。
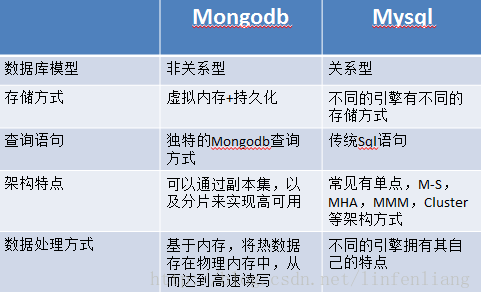

MongoDB和Hadoop的对比
1.基础定义
MongoDB:MongoDB是一种非关系型数据库,支持文档存储与查询,它非常适合存储JSON样式的文档,并且提供了强大的分片存储与查询功能。
Hadoop:Apache Hadoop是一个开源框架,它允许使用简单的编程模型进行分布式处理,Hadoop框架基于Java编程,专门用于存储和处理大规模数据集。
2.数据处理能力
MongoDB:MongoDB提供了内置的mapreduce功能,适用于历史数据(如日志)的存储与查询,尽管它在复杂计算上可能不如专门的计算框架,但其灵活性和易用性使其在许多场景下非常实用。
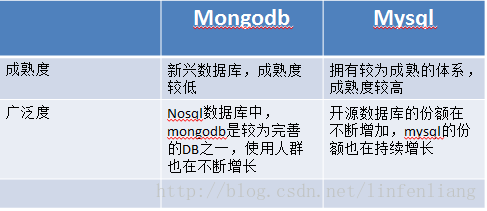
Hadoop:Hadoop通过HDFS(Hadoop Distributed File System)提供可靠的数据存储,并通过MapReduce编程模型支持复杂的数据分析,这使它能够有效地处理和分析大量数据。
3.适用场景
MongoDB:MongoDB适合需要快速读写、高性能的应用场景,例如实时分析、内容管理系统等,其复制集功能也确保了数据的高可用性。
Hadoop:Hadoop适用于数据密集型任务,如批量处理和离线分析,它的成本效益和扩展性使其成为处理大规模数据集的理想选择。
SQL on Hadoop的概念和应用
1.概念介绍

SQL on Hadoop:这是一种技术,允许用户直接在Hadoop上执行SQL查询,从而简化数据分析过程,它结合了传统关系型数据库的查询语言与Hadoop的强大数据处理能力。
2.工具和实现
Hive:Hive是最早实现SQL on Hadoop的工具之一,它将SQL查询转换为MapReduce任务,从而在Hadoop上执行。
Impala:Impala提供了低延迟的查询执行,它直接在Hadoop的HDFS上运行SQL查询,而无需MapReduce。
3.性能考量
查询优化:SQL on Hadoop的工具通常包含查询优化器,以提升查询效率和减少执行时间。
数据格式:使用如Parquet和ORC这样的列式存储格式,可以进一步提高查询性能。
MongoDB与Hadoop的结合
1.mongohadoop连接器
连接器作用:mongohadoop连接器是一个库,它允许Hadoop应用程序直接访问存储在MongoDB中的数据,这使得组合使用MongoDB的灵活数据模型和Hadoop的强大数据处理能力成为可能。
安装配置:将mongohadoop连接器的JAR文件放入Hadoop集群的lib目录,即可在Hadoop作业中调用MongoDB的数据。
2.数据处理流程
数据导入:数据可以从MongoDB导入到Hadoop进行处理,或者在MongoDB中进行初步处理后再导出到Hadoop进行深度分析。
结果回写:处理后的数据可以写回MongoDB,或者保存在Hadoop中,根据实际业务需求灵活处理。
问题与解答
1.问题一:如何选择合适的数据处理工具?
解答:首先考虑数据的类型和处理需求,如果需要实时或快速的数据处理,MongoDB可能是更好的选择,对于大规模的数据分析任务,特别是涉及复杂计算的,Hadoop将是更合适的选择。
2.问题二:使用SQL on Hadoop有哪些最佳实践?
解答:使用列式存储格式(如Parquet),合理配置资源,并利用查询优化工具,定期对Hadoop集群进行维护和监控,以确保查询性能和系统稳定性。
MongoDB和Hadoop虽然都是大数据技术,但各有特点和适用场景,了解它们的差异和优势可以帮助更好地选择和使用这些技术,通过SQL on Hadoop和mongohadoop连接器等工具,可以实现两者的有效结合,进一步提升数据处理的效率和灵活性,在选择数据处理工具时,应考虑具体的业务需求和数据类型,以达到最佳的处理效果。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/581024.html
 微信扫一扫
微信扫一扫