

详细解析MySQL和Hive数据库的导入导出操作
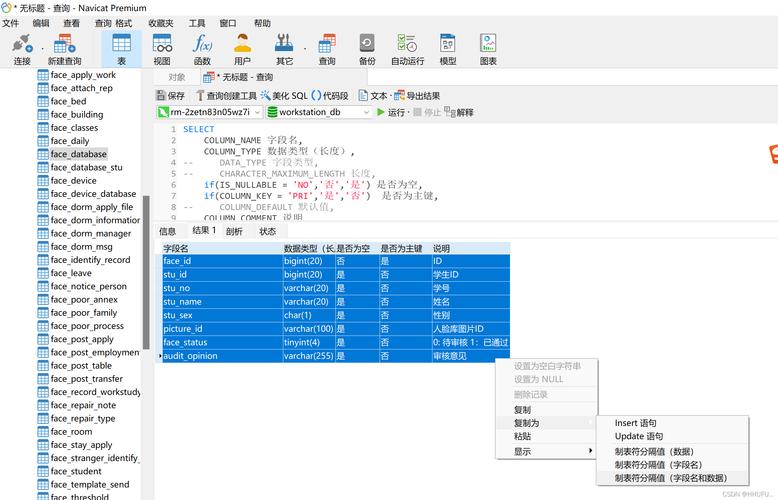

MySQL数据库的导入导出
1. 数据库导出方式
使用mysqldump工具:mysqldump是MySQL提供的备份数据库的命令行工具,支持导出整个数据库或特定的数据表,导出时,可以指定用户名、密码及要导出的数据库名和表名。
SELECT...INTO OUTFILE方法:适用于将选定的数据写入到一个文件中,文件通常保存在服务器主机上,并需要有文件写入权限,这种方式可以直接定义导出数据的范围和格式。
2. 数据导入操作
从sql文件导入:可以利用mysql命令执行sql文件,将数据导入到指定的数据库中。
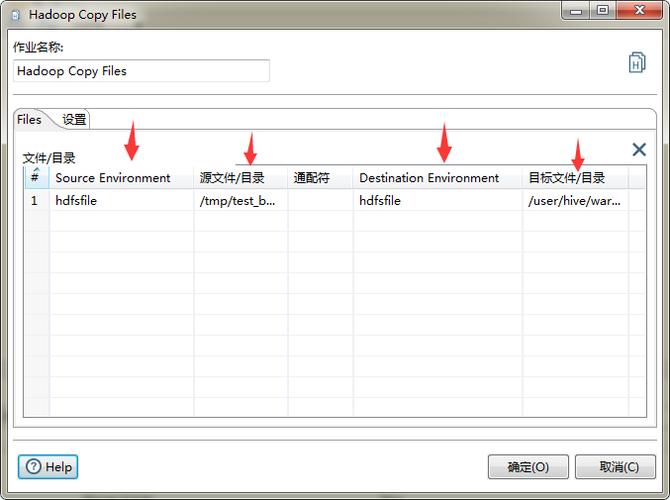
从本地或HDFS路径加载:通过LOAD DATA INPATH或LOAD DATA LOCAL INPATH语句,可以将本地文件系统或HDFS上的数据加载到MySQL表中。
Hive数据库的导入导出
1. 数据导出方法
INSERT OVERWRITE方式:可以将查询结果直接导出到本地文件系统或HDFS中,这个操作覆盖了目标位置的现有数据。
Exporting Data from Hive: 在Hive中,可以使用EXPORT TABLE命令将数据从Hive导出到HDFS路径中,这对于大数据集的导出非常有用。
2. 数据导入方式
从本地文件系统:可以使用LOAD DATA LOCAL INPATH命令将本地数据导入到Hive表中,这适用于数据量不大的情况。
从HDFS路径:使用LOAD DATA INPATH命令,当数据已在HDFS上时,这种方法非常高效,可以直接将数据移动到Hive表中。
应用实例
1. 场景描述
公司A需要进行数据分析:使用Hive对存储在HDFS上的大量日志进行分析,并将分析结果导出到MySQL数据库中供其他应用使用。
2. 操作步骤
数据导出: 在Hive中,使用INSERT OVERWRITE将分析结果导出到HDFS上的一个指定路径。
数据导入: 通过MySQL的LOAD DATA INPATH命令,将HDFS上的分析结果文件加载到MySQL数据库的指定表中。
常见问题与解答
1. mysqldump导出大数据量时性能缓慢,有何优化建议?
使用多线程备份:可以考虑使用像mydumper这样的第三方工具,它支持多线程备份,大大提高导出效率。
压缩备份文件:在导出时使用gzip等工具压缩备份文件,减少磁盘IO和网络传输时间。
2. Hive导出大量数据时遇到内存不足问题,如何解决?
分批次导出:将导出操作分为多个小批量进行,避免一次性处理大量数据造成的内存压力。
优化Hive配置:调整Hive配置参数,如mapreduce.map.memory.mb和mapreduce.reduce.memory.mb,增加运行map和reduce任务的内存。
希望以上内容能帮助您更好地理解MySQL和Hive数据库的导入导出操作,以及在实际场景中的应用方法。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/581700.html
 微信扫一扫
微信扫一扫