

1、基础概念
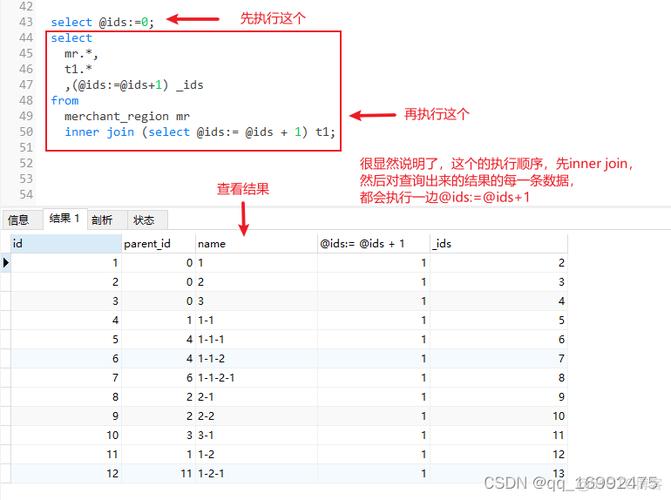
递归查询定义:递归查询是一种可以在查询过程中调用自身的查询,用于处理具有层次结构的数据,在MySQL中,递归查询通常通过使用特定的语法和函数来实现。
使用场景:递归查询常用于处理如组织架构、文件系统等具有自引用结构的数据模型,一个员工表中每个员工都有一个指向其上级的外键,这时就可以使用递归查询来获取某个员工的所有下属。
2、实现方法
with recursive关键字:在MySQL 8.0及以上版本中,可以使用WITH RECURSIVE语句来简化递归查询的编写,它允许查询在执行过程中引用自身的结果集。
find_in_set()和group_concat()函数:这两个函数虽不直接实现递归,但可以辅助进行数据聚合和条件判断,特别是在处理分隔符分隔的字符串列表时。
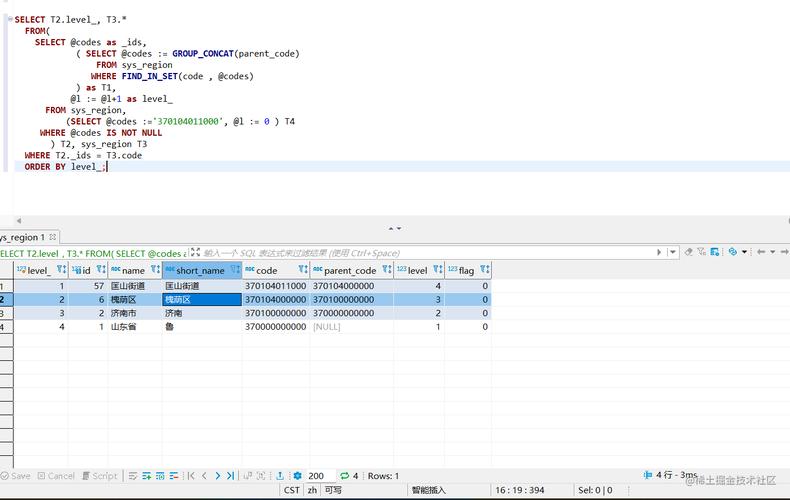
3、具体操作
创建递归表:首先需要有一个包含递归关系的表,如每个记录都包含一个指向其父记录的外键。
执行递归查询:使用WITH RECURSIVE语句,定义初始查询(种子查询)和递归部分(递归查询),然后执行这个构造好的查询。
4、递归终止与优化
递归终止条件:递归查询需要有明确的终止条件,否则可能导致无限循环,这通常是通过确保每次递归减少一定数量的数据或达到某个特定状态来实现。
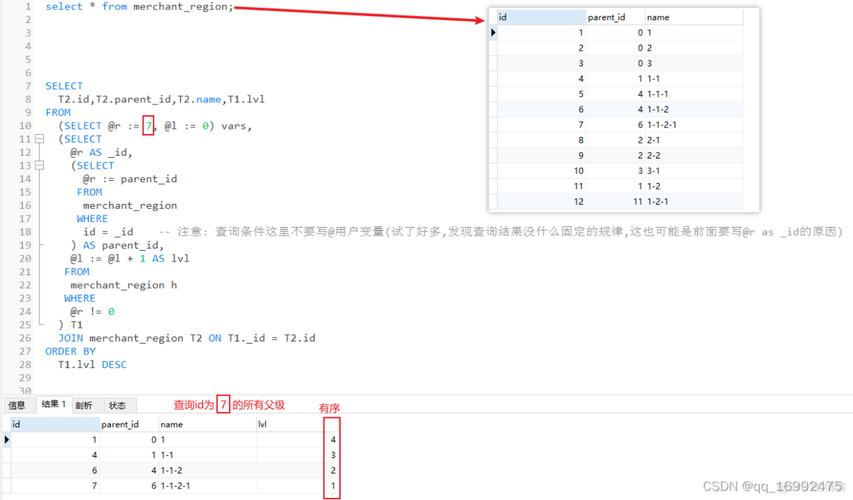
性能优化:为了提高递归查询的性能,可以通过限制递归深度、优化数据库索引等方法。
5、应用场景分析
组织结构查询:在一个员工表中,通过递归查询可以直接获取任意员工的完整下属链条。
路径查找:在图结构数据或具有多级关联的表中,递归查询可用于查找两个节点之间的所有可能路径。
6、相关工具与函数
存储过程:除了使用WITH RECURSIVE, 还可以通过编写存储过程来实现更复杂的递归逻辑,尤其是在处理多层级复杂关系时。
其他数据库系统的对比:虽然本讨论集中在MySQL上,但了解如Oracle的START WITH...CONNECT BY PRIOR等其他数据库的递归查询方法也是有益的。
相关问题与解答
Q1: 使用WITH RECURSIVE语句有哪些限制?
Q2: 如何优化递归查询的性能?
递归查询是处理具有层次结构数据的有力工具,尽管其实现方式多样,使用WITH RECURSIVE提供了一种标准化且简洁的方法,理解其原理和适用场景能够帮助更好地利用这一工具,同时注意性能优化和适当的应用场景选择也非常关键。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/582403.html
 微信扫一扫
微信扫一扫 