

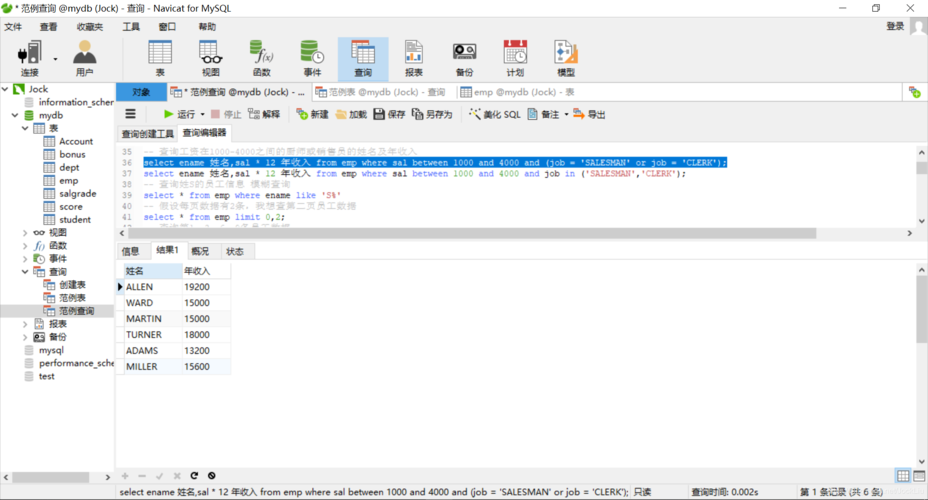
COUNT()函数。假设有一个名为transactions的表,其中包含交易数据,你可以使用以下SQL查询来统计结果条数:,,``sql,SELECT COUNT(*) FROM transactions;,``,,这将返回表中所有交易的总数。MySQL COUNT()函数查询表返回记录条数详解

简介
在数据库管理和应用开发中,统计查询结果的记录条数是一项基础而重要的操作,通过SQL的COUNT()函数,我们能够快速地获取到符合特定条件的记录数量。
COUNT() 函数基本用法
COUNT(*)对比COUNT(column_name)
COUNT(*) 返回表中所有记录的数量,包括NULL值在内。
COUNT(column_name) 返回指定列的值的数量,NULL值不包括在内。
这样,如果表中存在大量数据时,使用COUNT(*)可能会导致性能问题,尤其是当表包含大量列或索引时,一个优化策略是利用自增主键的特性,使用MAX(id) MIN(id) + 1或者直接MAX(id)来获取记录总量。
COUNT()函数高级应用
使用子查询和别名显示结果计数
通过结合子查询和别名,我们可以在查询结果中直接展示记录条数,这对于数据分析和报表生成非常有用。
查询区块、交易统计结果
在进行更复杂的数据统计分析时,GROUP BY子句与COUNT()函数的结合使用可以提供分组统计结果,如果我们想要统计每个区块的交易数量,可以使用以下语句:
SELECT block_id, COUNT(*) as transaction_count FROM transactions GROUP BY block_id;
这个查询将返回每个区块(block_id)及其相关的交易数量(transaction_count)。
相关统计函数
COUNT(DISTINCT column_name) 返回指定列的不同值的数目。
SUM(column_name) 计算指定列的数值总和。
AVG(column_name) 计算指定列的平均值。
MAX(column_name) 返回指定列的最大值。
MIN(column_name) 返回指定列的最小值。
掌握COUNT()函数的使用对于进行有效的数据库查询至关重要,无论是简单的记录统计还是复杂的数据分析,合理运用这些统计函数能够帮助用户深入理解数据,为决策提供支持。
相关问题与解答
Q1: COUNT(*)和COUNT(1)有区别吗?
A1: 两者在功能上没有区别,都可以用来统计表中的总记录数,但是在某些情况下,COUNT(*)可能会比COUNT(1)更快,因为它不需要检查每一行以确定是否有非NULL值。
Q2: 为什么有时使用COUNT(DISTINCT column_name)会比COUNT(*)慢得多?
A2: COUNT(DISTINCT column_name)需要对指定列中的值进行去重操作,这通常涉及到排序或使用临时存储空间,因此可能比简单的计数操作要慢,尤其是在大数据集上。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/583163.html
 微信扫一扫
微信扫一扫