

GROUP BY和HAVING子句。如果要检查表my_table中column1的重复值,可以使用以下查询:,,``sql,SELECT column1, COUNT(*) as count,FROM my_table,GROUP BY column1,HAVING count > 1;,``我们将深入探讨如何利用MySQL数据库来检测和处理重复数据的问题,针对不同类型的需求,比如单列重复检测、多列重复检测以及如何删除或保留特定的重复记录,我们提供了一系列实用的SQL查询语句和操作步骤,通过这些方法,可以有效地管理和优化数据库中的数据。
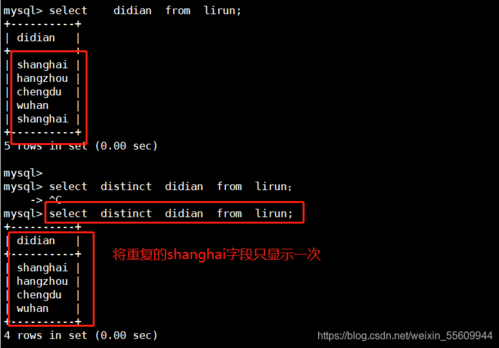

单列重复数据检测
当需要检测数据库中某一列的重复数据时,可以使用以下SQL查询语句:
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name HAVING COUNT(*) > 1;
替换column_name和table_name:将column_name替换为你想要检查重复的列的名称,将table_name替换为目标表名。
查询逻辑:此查询首先根据指定的列对数据进行分组,然后使用HAVING子句筛选出那些出现次数大于1的记录,即存在重复值的记录。
多列重复数据检测
当需要基于多个列来确定数据是否重复时,可以使用以下查询:
SELECT column1, column2, COUNT(*) FROM table_name GROUP BY column1, column2 HAVING COUNT(*) > 1;
替换column1、column2和table_name:将column1,column2替换为你打算检查重复的列的名称,table_name替换为目标表名。
查询逻辑:类似于单列查询,这个查询通过GROUP BY子句按多个列进行分组,并通过HAVING子句找出至少出现两次的记录。
删除或保留非重复记录
在确定了重复记录后,你可能需要删除多余的记录或仅保留一条记录,这可以通过结合使用DELETE和SELECT语句实现:
保留一条非重复记录
1、查找重复记录并保留一条
```sql
SELECT MIN(column1), column2
FROM table_name
GROUP BY column2;
```
2、删除其他记录
```sql
DELETE FROM table_name
WHERE (column1, column2) NOT IN (
SELECT MIN(column1), column2
FROM table_name
GROUP BY column2
);
```
操作步骤:首先运行选择查询来找出每组重复中的最小(或最大,取决于需求)记录,然后通过DELETE语句删除不在这个列表中的记录。
在掌握了如何检测和处理重复数据的基本方法后,让我们通过一些实际例子来进一步理解这些操作。
实际应用场景
假设我们有一个名为"students"的数据库表,其中包含学生的信息,如学号、姓名等,如果我们想要找出所有同名的学生,我们可以使用多列重复数据检测的方法,如果我们有一个销售数据的表,我们可能想要找出所有销售额相同的产品,这也可以利用上述方法轻松实现。
相关问题与解答
Q1: 如果在检测到重复数据后,我只想查看这些数据而不做任何删除操作,我应该怎么办?
Q2: 如果我想要找出表中所有的唯一记录,没有重复的那些,应该如何操作?
答案:
A1: 你可以直接使用我们在“多列重复数据检测”部分提到的查询语句来查看重复数据,不需要后续的删除操作,如果你希望跟踪这些记录,可以考虑创建一个新表来存储这些重复记录,或者简单地将结果输出到一个CSV文件中以便后续分析。
A2: 要找出没有重复的唯一记录,可以在上述查询的基础上稍作修改,改为查找出现次数等于1的记录:
```sql
SELECT column1, column2, COUNT(*) as Count
FROM table_name
GROUP BY column1, column2
HAVING Count = 1;
```
通过本文的介绍,我们了解了如何使用MySQL数据库来检测和处理重复数据,从基本的单列和多列重复数据检测,到如何删除或保留特定的重复记录,各种方法和技巧都旨在帮助数据库管理员维护数据的准确性和清洁度。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/583223.html
 微信扫一扫
微信扫一扫