

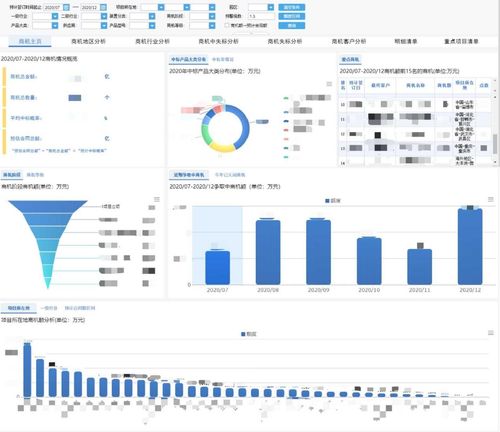

【流数据与批处理数据对比】
流数据与传统的批处理数据在数据处理方式上有本质的不同,批处理数据处理的是一组固定的、不会变化的数据集合,而流数据则是源源不断地实时产生,需要即时处理,这种区别带来了两者在处理实时性、顺序性和增量式处理上的根本差异。
【流数据的三大核心特征】
1、实时性
流数据要求对数据进行即时处理,以便快速做出响应,金融市场的股价更新需实时分析以指导交易。
2、顺序性
流数据保持事件的发生顺序,这对于事件结果的因果推理至关重要,如用户界面点击流数据的顺序反映了用户的使用习惯。
3、增量式处理
流数据不需要一次性加载所有数据,而是随数据的产生逐步进行处理,大大节省了资源消耗。
【流数据来源及应用实例】
流数据可以来源于多个渠道,包括但不限于传感器数据、社交媒体消息、金融交易和网络日志等,物联网设备产生的实时数据可用于监控环境变化;网站点击流数据分析可优化用户体验。
【流数据处理技术挑战】
由于流数据的持续抵达、易失性和突发性,传统的数据分析工具往往不适用,需要开发新的技术和工具来满足流数据的处理需求,这包括高效的数据采集系统和实时的数据分析算法。
【流数据处理的价值所在】
流数据处理的核心价值在于能够从动态变化的数据中快速提取信息,并做出相应的动作或决策,它侧重于数据的整体价值而非个别数据点,这对于需要迅速反应的场景尤其重要。
【归纳与未来展望】
随着技术的发展,流数据处理正在变得越来越重要,它不仅能提供实时的业务洞察,还能驱动自动化决策过程,随着5G等更快的网络技术的普及,流数据处理将更加普遍且高效。
【相关挑战】
1、如何确保流数据处理系统在各种流量条件下的稳定性和可靠性?
2、针对数据质量不一的情况,如何设计算法来确保分析结果的准确性?
【解答】
1、设计高可用和容错性强的系统架构是关键,采用微服务架构和容器化部署可以提高系统的灵活性和稳定性,实施实时监控和自动扩缩容策略,可以动态调整资源以应对不同的流量负载。
2、引入数据清洗和预处理步骤是必要的,可以使用机器学习模型来识别和纠正异常数据,提高数据分析的质量,结合多种数据验证方法,如交叉验证和外部数据对照,可以进一步保证分析结果的稳健性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/583671.html
 微信扫一扫
微信扫一扫