

在Linux系统中,管道(Pipe)是一种重要的数据流转向手段,主要用于连接两个或多个命令,使得前一个命令的输出可以直接作为后一个命令的输入,管道的使用大大提高了命令行操作的效率和简洁性,它通过减少数据在不必要的存储过程中的读写,优化了数据处理流程,具体如下:

1、管道的基础概念
定义与作用:管道操作符在Linux中用“|”表示,其核心作用是使一个命令的输出可以直接作为另一个命令的输入。
无名管道与有名管道:管道分为无名管道和有名管道,其中无名管道常用于具有亲缘关系的进程间通信,而有名管道则以文件形式存在,使用范围更广。
语法格式:基本的管道语法格式为command1 | command2,并且可以通过连续使用管道符来链接多个命令,如command1 | command2 | commandN等。
2、管道的工作原理
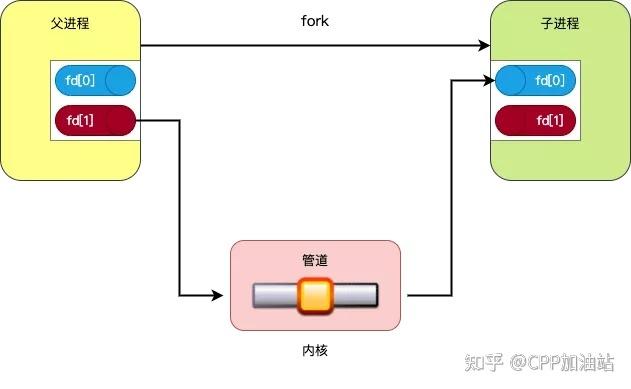
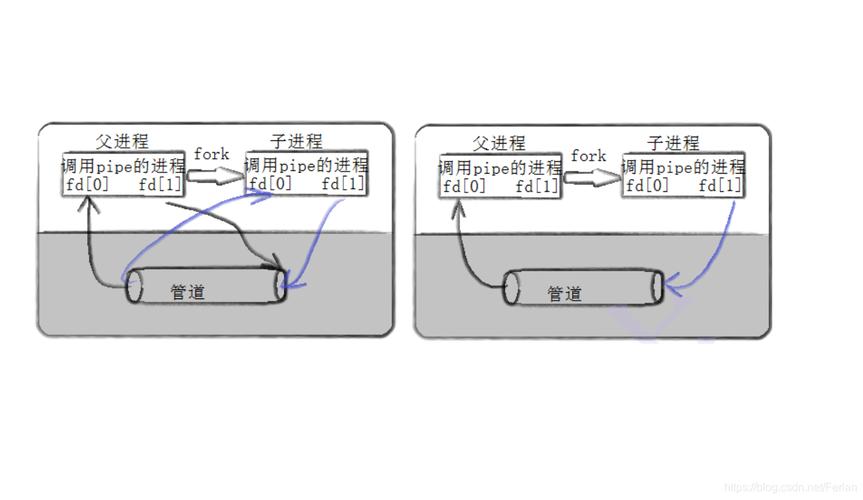
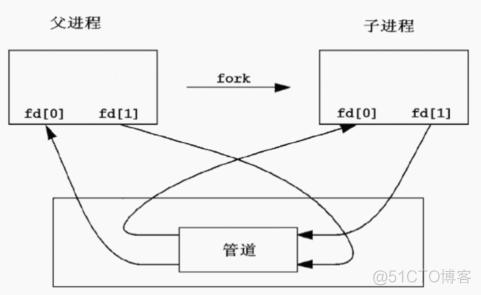
数据流向:在管道操作中,数据从左侧命令的输出流向右侧命令的输入,左侧命令产生的数据不会保存在磁盘上,而是直接通过内存传递到右侧命令,从而加快处理速度并降低资源消耗。
进程间通信:管道实际上是通过系统内核在进程间传递数据的一种方式,当命令通过管道连接时,它们运行在独立的进程空间内,内核负责协调数据的传递。
3、管道的操作与应用
过滤与处理数据:通过管道,用户可以组合各种命令来实现复杂的数据处理任务。cat hello.sh | sort | uniq | grep 'better'这个命令链可以对文件内容进行排序、去重并筛选含有'better'的行。
简化复杂命令:管道使得原本需要多步骤完成的任务可以在一行命令中完成,减少了脚本编写的复杂度,提高了工作效率。
实时数据处理:管道支持实时数据处理,不需要预先存储大量数据,这对于处理大数据量或实时数据流非常有用,比如日志处理或数据监控场景。
4、高级管道应用技巧
使用工具命令:管道经常与grep,awk,sed等文本处理工具联合使用,实现强大的文本处理功能,如文本替换、数据提取和复杂查询等。
链式管道:在复杂的数据处理中,可以创建链式管道,例如tar xf myarchive.tar | grep 'important' | sort > result.txt,这种链式管道可以解压缩文件、搜索关键词并进行排序,最后输出到指定文件。
5、管道与重定向的结合使用
标准输入输出重定向:管道常常与标准输入输出(stdin/stdout)的重定向结合使用,例如>和>>用于将输出重定向到文件,而<则用于从文件读取输入。
错误流的处理:在管道操作中,错误信息通常通过标准错误(stderr)输出,可以使用2>来重定向错误信息,如command1 | command2 2> error.log可以将错误信息单独记录。
Linux管道的作用在于提供了一个高效且灵活的命令执行方式,允许用户无缝地连接多个命令来处理数据,通过这种方式,Linux用户可以轻松地构建数据处理的流水线,从而提高工作的效率和准确性,掌握管道的使用不仅可以优化日常的数据处理任务,还可以在自动化脚本和复杂数据处理中发挥重要作用。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/584155.html
 微信扫一扫
微信扫一扫