

在Linux系统中,IO多路复用技术是一种高效的网络编程手段,主要用于同时处理多个网络连接,这种机制允许开发者使用单线程或单进程来管理多个文件描述符,尤其是对于高并发的服务器应用而言,IO多路复用大大提高了程序的效率和性能,本文将深入探讨Linux中IO多路复用机制,特别关注epoll的使用及其与缓存和IO操作的关系。

IO多路复用机制主要通过select、poll和epoll三个函数实现,这些函数允许进程或线程监视多个文件描述符的状态,当一个或多个文件描述符准备就绪时(即可读或可写),系统会通知程序进行相应的读写操作。
1、IO多路复用的基本原理
工作原理:通过一种机制,让单个进程可以同时监控多个文件描述符的状态,当其中某个描述符准备好进行IO操作时,程序会被通知进行相应的读写处理。
API提供方式:Linux提供了select、poll、epoll等多种API来实现IO多路复用,每种方式各有特点和适用场景。
2、Select、Poll和Epoll的区别与联系

Select:是最基本的IO多路复用机制,能监控多个文件描述符,但存在最大文件描述符数量限制,且效率较低,因为每次调用都需要遍历所有描述符。
Poll:作为select的改进版,解决了文件描述符数量的限制,但仍然需要遍历所有描述符,效率问题依旧存在。
Epoll:是Linux特有的高效IO多路复用机制,采用事件驱动方式,只关注已准备好的描述符,大大减少了开销,适用于高并发场景。
3、Epoll的工作原理及优势
事件驱动:epoll使用事件队列来避免遍历所有监控的文件描述符,只有当描述符状态发生变化时才进行处理,显著提高了效率。
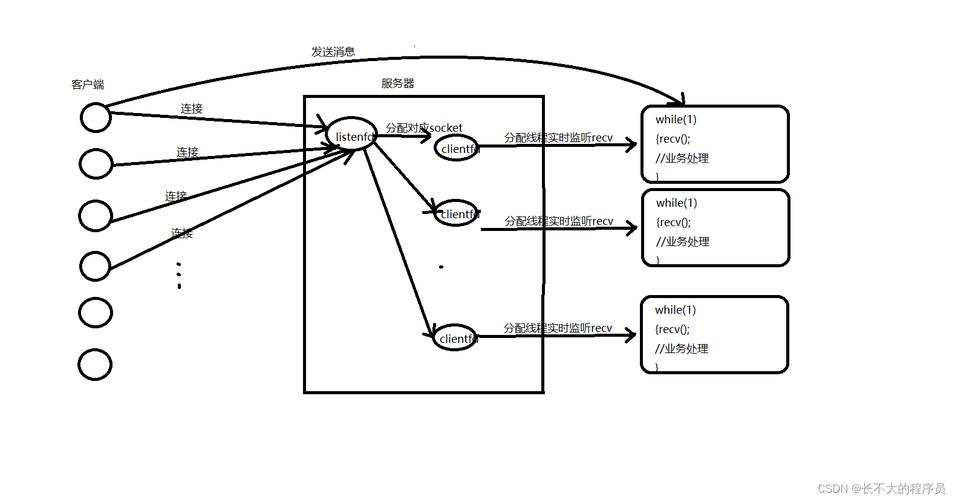
内核支持:epoll由Linux内核直接支持,能够更快速地响应网络请求,尤其是在大量并发连接的情况下,性能明显优于select和poll。
4、缓存与IO多路复用的关系
数据缓存:操作系统为提高IO效率,会对数据进行缓存,在IO多路复用中,缓存可以减少实际的磁盘IO操作,提升数据读取速度。
缓存一致性:使用IO多路复用时需注意缓存数据的一致性问题,确保应用层与内核空间的数据同步。
5、IO多路复用与异步IO的区别
异步程度:虽然IO多路复用增加了程序的并发处理能力,但它仍采用的是阻塞式系统调用,因此只能算作异步阻塞IO,并非真正的异步IO。
系统支持:真正的异步IO需要操作系统更深层次的支持,通过信号或回调机制来通知程序IO操作的完成。
在此基础上,可以提出两个与Linux中IO多路复用机制相关的问题,并给出答案。
问:Epoll相比Select和Poll在处理高并发场景时有哪些显著优势?
答:Epoll的优势在于其高效的事件驱动机制和内核的支持,它避免了不必要的文件描述符遍历,仅处理已准备好的描述符,大大减少了CPU和系统资源的消耗,特别是在处理大量并发连接时,epoll能显著提高程序的性能和响应速度。
问:在使用Epoll进行IO多路复用时,如何有效利用操作系统的缓存机制?
答:在使用epoll时,可以通过调整内核的TCP参数来优化缓存行为,如修改SO_RCVBUF和SO_SNDBUF来调整接收和发送缓冲区的大小,确保应用程序正确处理数据读取,避免因缓存机制导致的数据不一致问题。
Linux中的IO多路复用机制,特别是epoll的使用,为现代网络编程带来了极大的便利和效率提升,通过合理利用这一机制,开发者可以在保证性能的同时,简化程序设计,更好地处理高并发的网络服务需求。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/585514.html
 微信扫一扫
微信扫一扫