

mysql命令行工具。首先确保已经安装了MySQL服务器和客户端,然后使用以下命令导入数据库:,,``bash,mysql u 用户名 p 数据库名< 数据库文件.sql,``,,将“用户名”替换为实际的MySQL用户名,“数据库名”替换为目标数据库的名称,“数据库文件.sql”替换为要导入的数据库文件。在执行此命令时,系统会提示输入密码。Linux下导入数据库的方法与Linux下编译流程

导入数据库
在Linux系统中,数据管理通常离不开数据库的导入和导出操作,本文旨在详细介绍在Linux环境下如何导入数据库,以及Linux下的编译流程。
1. 方法一:使用source命令
利用MySQL的命令行工具,可以使用source命令来导入sql文件,这个方法简单直接,适用于已经本地化的数据库备份文件。
步骤包括:首先登录到mysql,然后选择目标数据库,最后使用source命令指定sql文件路径执行。
2. 方法二:使用mysql命令
通过在终端中输入一系列的命令,可以实现数据库的导入,这种方法可以在不进入mysql客户端的情况下完成数据库的导入。
具体命令格式为:mysql u用户名 p密码 数据库名 < 数据库文件,这种方式可以快速地将数据库备份恢复到指定的数据库中。
3. 使用LOAD DATA INFILE语句
对于大量的数据导入,MySQL提供了LOAD DATA INFILE语句,可以直接从文本文件中读取数据并插入到数据库表中。
该方法避免了逐条插入记录的性能消耗,特别是在处理大量数据导入时显示出其优势。
4. 使用mysqlimport工具
mysqlimport是一个用于导入文本文件到MySQL数据库的命令行工具,它提供了一个自动化的方式来导入CSV等格式的数据文件。
它支持多种选项,如指定字符集、字段分隔符等,使得数据导入更加灵活和高效。
Linux下编译流程
在Linux系统下,编译流程是程序开发的重要环节,涉及多个关键步骤。
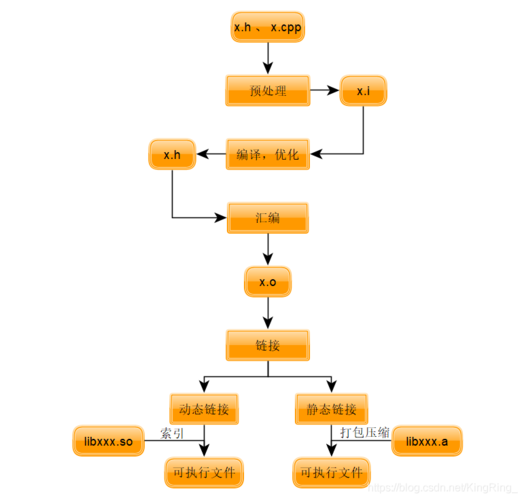
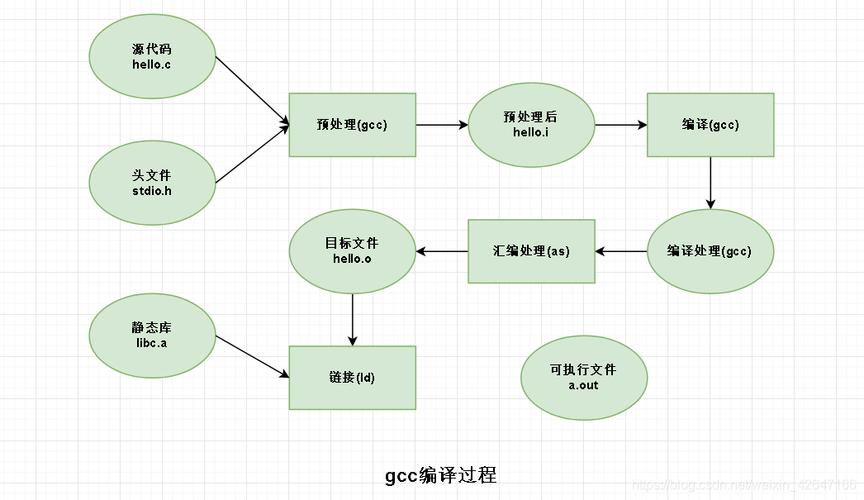
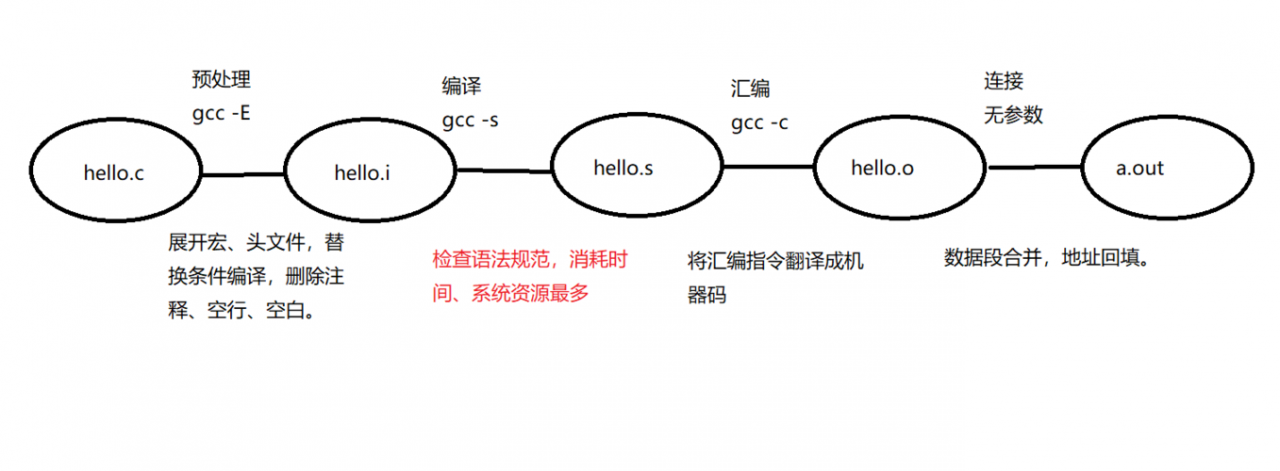
1. 预处理阶段
预处理主要处理源代码中的预处理指令和宏定义,通过预处理器,将所有的#include、#define进行展开和替换。
此过程可能涉及到文件的包含、条件的编译等,最终生成一个没有宏定义和#include语句的C文件。
2. 编译阶段
编译器将经过预处理的文件转换成汇编语言代码,这一步骤是编译过程的核心,涉及到语法分析、词法分析等复杂的编译技术。
通过编译器(如gcc)生成对应的.s文件,等待进一步的汇编。
3. 汇编阶段
汇编器将汇编代码转换为机器码,生成目标文件(通常是.o文件),这个过程相对直接,因为汇编语言与机器语言之间存在直接的对应关系。
4. 链接阶段
链接器将各个目标文件及库文件链接成一个可执行文件,这个阶段主要解决程序中的外部符号引用问题,确保程序能够在运行时正确调用到相关函数和变量。
全面介绍了在Linux环境下导入数据库的多种方法和详细的Linux下编译流程,通过这些信息,用户可以更有效地管理和编译其数据库和源代码,优化日常的数据处理和软件开发任务。
注意事项
确保mysql服务正在运行,否则无法通过命令行进行数据库的导入操作。
在编写sql文件时,要确保编码方式与数据库设置一致,避免出现乱码或错误。
在编译过程中,应确保所有依赖的库文件和头文件路径设置正确,避免编译错误。
本文详细探讨了在Linux环境下导入数据库的几种有效方法,以及Linux下编译流程的关键步骤,了解这些操作对于在Linux系统上进行数据库管理和软件开发至关重要,用户应根据具体需求选择最合适的方法和步骤,以确保数据安全和软件质量。
相关问答
Q1: 如果数据库文件很大,导入过程中遇到性能瓶颈该如何解决?
Q1: 可以考虑使用LOAD DATA INFILE命令,该命令可以直接从文本文件导入数据,比逐条插入效率更高,适当调整MySQL的配置参数,如缓冲区大小等,也可以提高导入效率。
Q2: 在Linux编译过程中,如果遇到编译错误应该如何排查?
Q2: 首先检查源代码是否有语法错误或逻辑错误;其次确认所有的库和头文件是否在正确的位置;最后查看编译器的版本是否与代码兼容,使用编译器的详细输出选项(如添加Wall参数)可以帮助快速定位问题所在。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/585586.html
 微信扫一扫
微信扫一扫