

MapReduce Job作用与配置基线
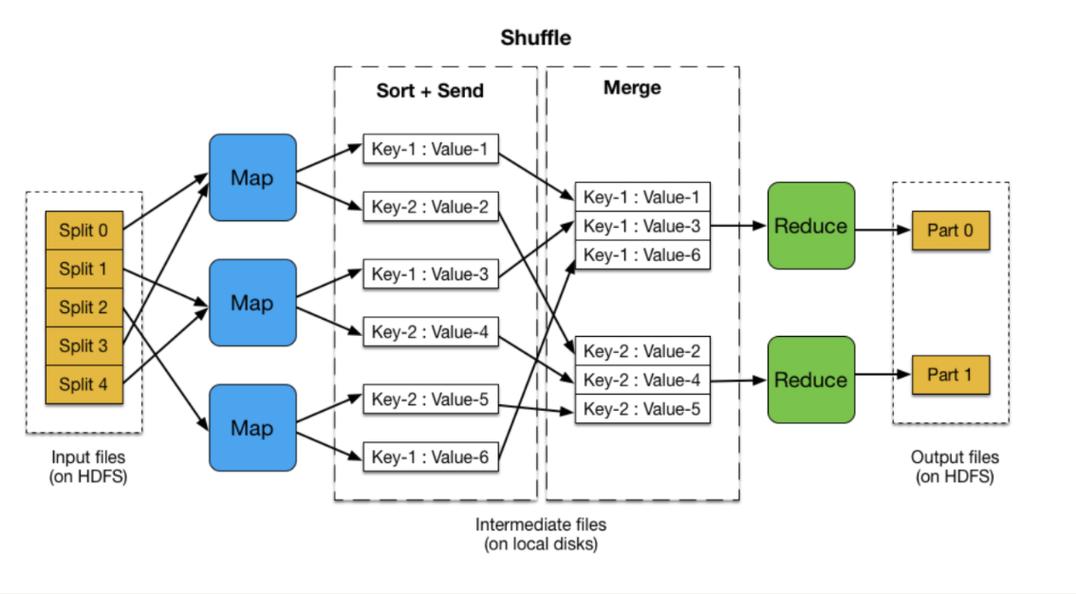
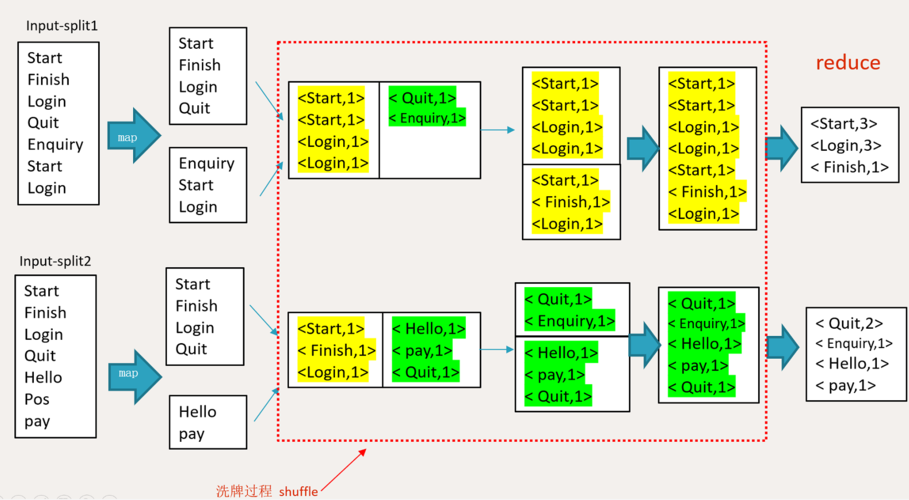
MapReduce是一种编程模型,用于处理和生成大数据集,它包含两个主要阶段:Map阶段和Reduce阶段,Map阶段将输入数据拆分为独立的数据块,然后由多个Map任务并行处理,Reduce阶段则负责对Map阶段的输出进行汇总,以得到最终结果。
MapReduce作业(Job)的作用
数据分发: MapReduce框架自动将输入数据分片,并分配给各个Map任务。
并行处理: 每个Map任务独立处理一个数据分片,可以在不同的节点上同时运行。
结果整合: Reduce任务负责接收来自各个Map任务的输出,并进行汇总处理。
配置MapReduce Job基线
为了高效运行MapReduce作业,需要对Job进行适当的配置,以下是一些关键参数的配置基线:
1. 输入输出配置
| 参数 | 描述 |
| input path | HDFS中的输入文件路径 |
| output path | HDFS中的输出文件路径 |
| input format | 用于读取输入数据的格式 |
| output format | 用于写入输出数据的格式 |
2. Map配置
| 参数 | 描述 |
| mapper class | 实现Mapper接口的类 |
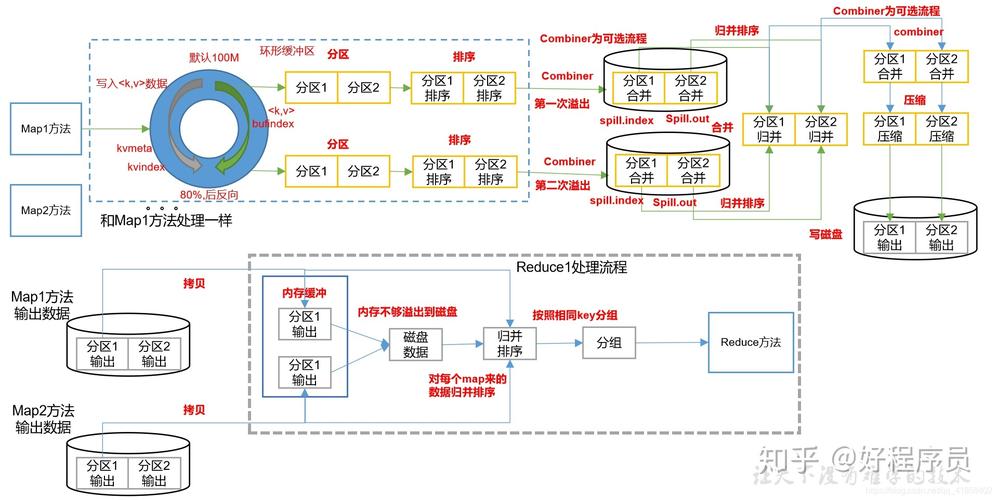
| combiner class | 可选,用于本地聚合Map输出以减少网络传输量 |
| map output key class | Map输出键的数据类型 |
| map output value class | Map输出值的数据类型 |
3. Reduce配置
| 参数 | 描述 |
| reducer class | 实现Reducer接口的类 |
| number of reducers | Reduce任务的数量 |
| reduce input key class | Reduce输入键的数据类型 |
| reduce input value class | Reduce输入值的数据类型 |
| sort comparator class | 可选,用于自定义排序比较器 |
| grouping comparator class | 可选,用于自定义分组比较器 |
4. 其他配置
| 参数 | 描述 |
| job name | 作业的名称 |
| jar by class | 包含作业类的jar文件 |
| file output format | 输出文件的格式 |
| compression codec | 压缩编解码器,用于压缩Map输出和最终输出 |
相关问题与解答
Q1: 如果MapReduce作业运行缓慢,可能的原因是什么?
A1: 可能的原因包括:
数据倾斜:某些Key对应的数据量远大于其他Key,导致个别Reduce任务处理时间较长。
资源分配不足:集群资源(如内存、CPU)不足以支持当前的作业并发度。
I/O瓶颈:磁盘读写速度或网络带宽成为限制因素。
不合理的配置:如设置了过多的Reduce任务,增加了任务启动和调度的开销。
Q2: 如何优化MapReduce作业的性能?
A2: 优化方法包括:
调整Reduce数量:根据实际数据分布和集群资源情况调整Reduce任务数。
使用Combiner:在Map端进行局部聚合,减少数据传输量。
合理设置数据格式:选择合适的输入输出格式以提高数据处理效率。
数据预处理:在运行作业前进行数据清洗和格式化,避免作业中不必要的计算。
考虑数据本地化:尽量让数据在存储它的节点上进行处理,减少网络传输。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/585779.html
 微信扫一扫
微信扫一扫 