

MapReduce任务可以通过配置使用分布式缓存来执行。将需要缓存的文件打包成tarball格式。在MapReduce作业的配置中,设置分布式缓存的路径为tarball文件的位置。在Mapper或Reducer中,通过DistributedCache类获取缓存文件,并进行相应的处理。
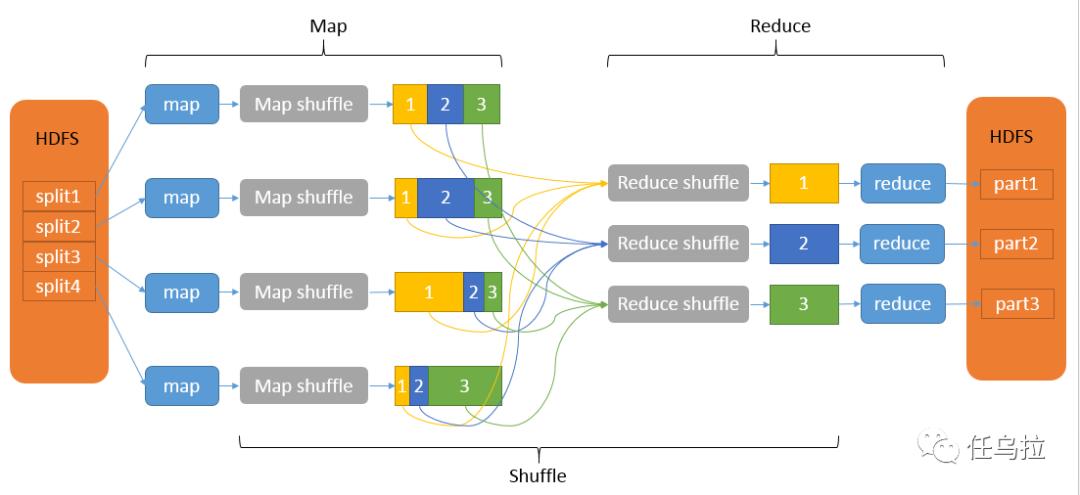
使用分布式缓存执行MapReduce任务

(图片来源网络,侵删)
1. 配置分布式缓存
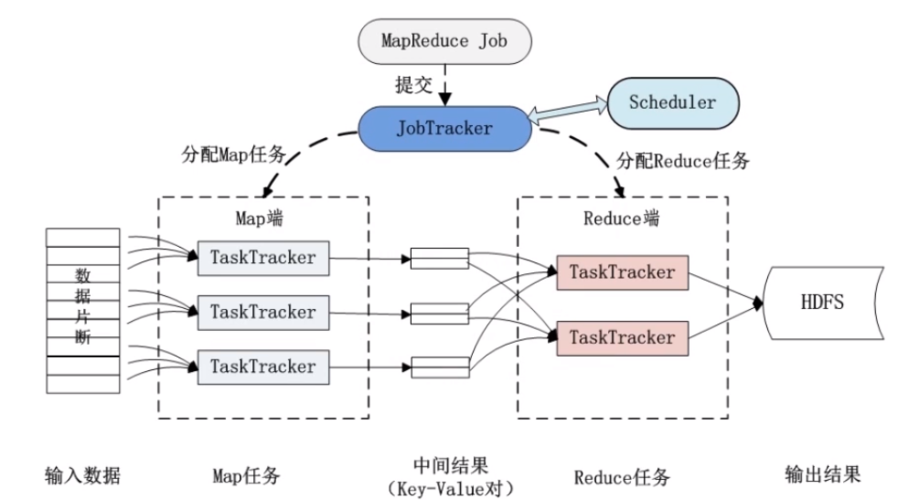
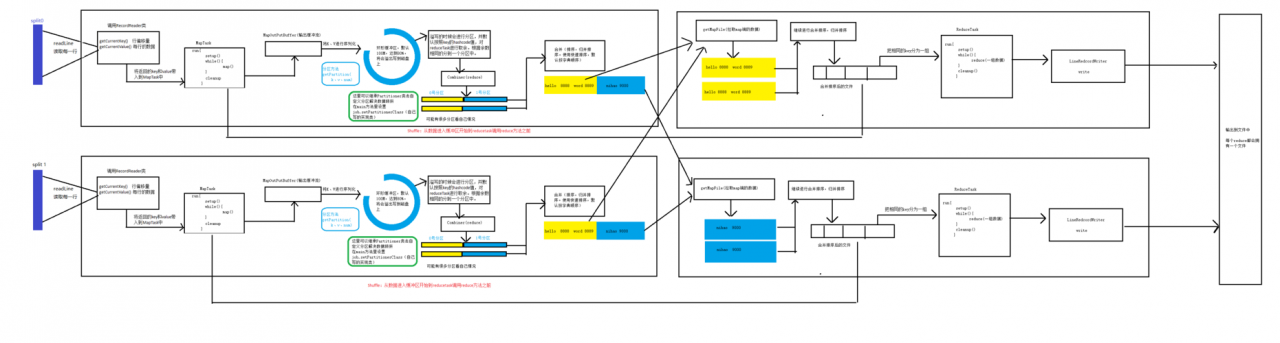
在Hadoop中,分布式缓存允许用户将文件或目录添加到集群的每个节点上,这些文件可以在MapReduce任务中使用,而无需在网络上传输数据,以下是如何配置和使用分布式缓存的步骤:
步骤1: 准备要缓存的文件
你需要确定要在分布式缓存中使用的文件,这些文件可以是任何类型的文本文件、序列化对象或其他可以被Hadoop处理的数据格式。
步骤2: 添加分布式缓存配置
(图片来源网络,侵删)
在你的MapReduce程序中,你需要设置分布式缓存的配置,这可以通过Job类的addCacheFile(URI uri)方法来完成。
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "My MapReduce Job");
// ...其他作业配置...
job.addCacheFile(new Path("/path/to/your/cache/file").toUri());
步骤3: 在Mapper和Reducer中使用缓存文件
一旦你配置了分布式缓存,你可以在你的Mapper和Reducer类中使用它,你可以使用DistributedCache类来访问缓存的文件。
public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
private HashMap<String, Integer> aMap;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
aMap = new HashMap<>();
Path[] cacheFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration());
if (cacheFiles != null && cacheFiles.length > 0) {
// 读取缓存文件并填充HashMap
// ...
}
}
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 使用aMap进行映射操作
// ...
}
}
2. 示例代码
以下是一个使用分布式缓存的简单MapReduce程序示例:
(图片来源网络,侵删)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class DistributedCacheExample {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: DistributedCacheExample <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "Distributed Cache Example");
job.setJarByClass(DistributedCacheExample.class);
job.setMapperClass(MyMapper.class);
job.setCombinerClass(MyReducer.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 添加分布式缓存文件
job.addCacheFile(new Path("/path/to/your/cache/file").toUri());
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
相关问题与解答
问题1: 分布式缓存中的文件大小有限制吗?
答案1: 是的,Hadoop分布式缓存中的单个文件大小默认限制为64MB,如果需要缓存更大的文件,可以通过修改配置文件中的mapreduce.cluster.local.dir属性来增加缓存大小。
问题2: 分布式缓存中的文件是否在所有节点上都可用?
答案2: 是的,分布式缓存中的文件会被复制到集群的所有节点上,因此所有节点都可以访问这些文件,这使得分布式缓存非常适合存储大型数据集或共享资源,而无需在网络上传输数据。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/585802.html
 微信扫一扫
微信扫一扫