

关于MapReduce中的Reduce任务数量,这是一个值得关注的问题,因为它直接影响着数据处理的效率和效果,在MapReduce框架中,Reduce阶段紧随Map阶段之后,主要负责处理Map阶段的输出结果,对其进行归纳、排序和合并等操作,小编将详细探讨MapReduce中Reduce的数量设置及其影响因素:
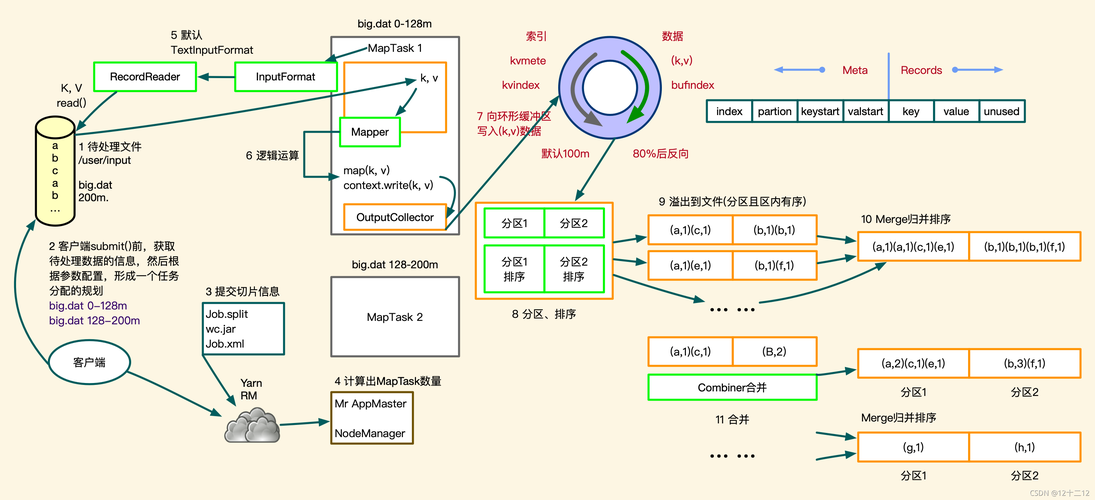

1、设置Reduce数量
配置参数:可以通过Hive中的SET mapreduce.job.reduces=<number>;命令来手动设定Reduce任务的数量,这一命令允许用户根据具体的作业需求和集群资源情况来调整Reduce任务的数量。
默认值:如果在Hive或其他相似的系统中未显式设置Reduce的数量,则系统通常会采用一个默认值或根据数据大小和集群配置自动进行优化选择。
2、考虑因素
数据大小:输入数据的总大小是决定Reduce任务数量的重要因素之一,较大的数据集通常需要更多的Reduce任务来并行处理,以缩短处理时间。
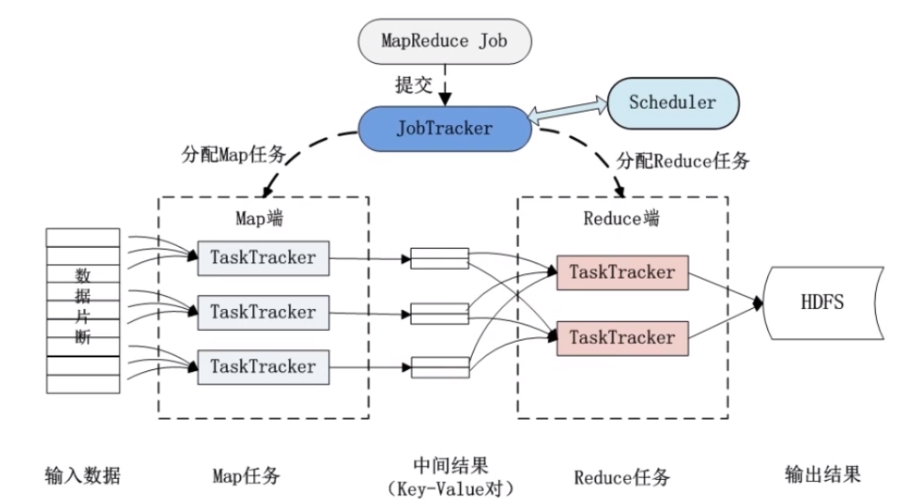
预期输出:如果预期的输出结果需要更细致的分类或分组,可能需要增加Reduce任务的数量以确保每个任务处理的数据量不会过大。
资源限制:集群的资源限制(如内存和处理器能力)也会对可同时运行的Reduce任务数量造成影响,过多的Reduce任务可能会导致单个节点上的资源竞争,从而影响性能。
网络带宽:在分布式计算环境中,数据的传输速度也会影响Reduce任务的执行效率,网络带宽的限制可能导致数据传输成为瓶颈,特别是在大数据量处理时。
3、优化策略
负载均衡:合理设置Reduce任务的数量可以帮助实现集群的负载均衡,避免某些节点过载而其他节点空闲的情况。
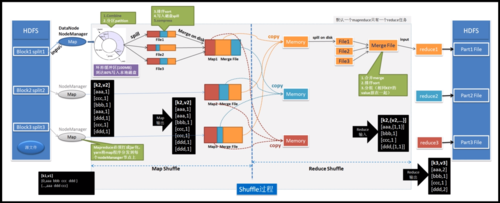
容错性:通过增加Reduce任务的数量,可以在一定程度上提高作业的容错性,因为单个任务的失败不会导致整个作业失败。
性能监控:持续监控MapReduce作业的性能,根据实际运行情况调整Reduce任务的数量,以达到最优的处理效率。
MapReduce框架提供了灵活的Reduce任务数量设置选项,使得用户可以根据具体的需求和资源状况进行优化配置,正确设置Reduce任务的数量对于提高数据处理效率、优化资源使用以及保证作业成功完成至关重要。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/585923.html
 微信扫一扫
微信扫一扫