

MapReduce是一种编程模型,用于处理大量数据。Java是一种编程语言。MapReduce Java API接口是Java语言中实现MapReduce编程模型的一套接口,它允许开发者使用Java编写MapReduce程序来处理大规模数据集。
MapReduce和Java的对比

(图片来源网络,侵删)
MapReduce是一种分布式计算框架,而Java是一种通用编程语言,它们在定义、设计模型以及处理数据类型等方面有所区别,具体分析如下:
| 标题 | MapReduce | Java |
| 定义 | MapReduce是一个由Google提出的编程模型,专门用于处理和生成大数据集。 | Java是一种广泛使用的高级编程语言,具有跨平台的能力,可以创建各种类型的应用程序。 |
| 设计模型 | MapReduce采用了“分而治之”的设计思想,通过Map和Reduce两个阶段来处理数据。 | Java遵循面向对象的编程范式,支持封装、继承和多态等特性。 |
| 处理数据类型 | 主要处理大规模数据集,适用于批量数据处理。 | Java提供多种数据类型,能够处理不同规模和类型的数据。 |
| 性能考量 | 设计用于并行处理,提高大数据处理的效率和吞吐量。 | Java的性能依赖于单线程或多线程的实现,适用于多种运行环境。 |
| 适用范围 | 不适用于需要实时计算的场景。 | Java可用于开发桌面应用、Web应用、移动应用等多种场景。 |
MapReduce Java API接口介绍
使用Java编写MapReduce程序时,可以通过Hadoop MapReduce的Java API来实现,以下是API接口的介绍:
| 功能 | 接口/类 | 描述 |
| Map函数实现 | Mapper | 用于处理输入数据并生成中间结果的键值对 |
| Reduce函数实现 | Reducer | 用于处理Mapper的输出,并根据键进行聚合操作 |
| 作业配置与执行 | Job | 配置MapReduce作业的相关参数,如输入输出路径、Mapper和Reducer类等 |
| 数据类型与格式 | InputFormat, OutputFormat | 指定数据的输入输出格式,影响数据的读取和写入方式 |
| 其他工具类 | Configuration, FileSystem, Path | 辅助类,帮助进行配置管理、文件系统操作等 |
相关问题与解答
MapReduce是否可以用Java以外的语言实现?
(图片来源网络,侵删)
答: 是的,虽然MapReduce最初是为Java设计的,但也可以通过其他支持Hadoop接口的语言实现,例如Python通过Hadoop Streaming或Pipes。
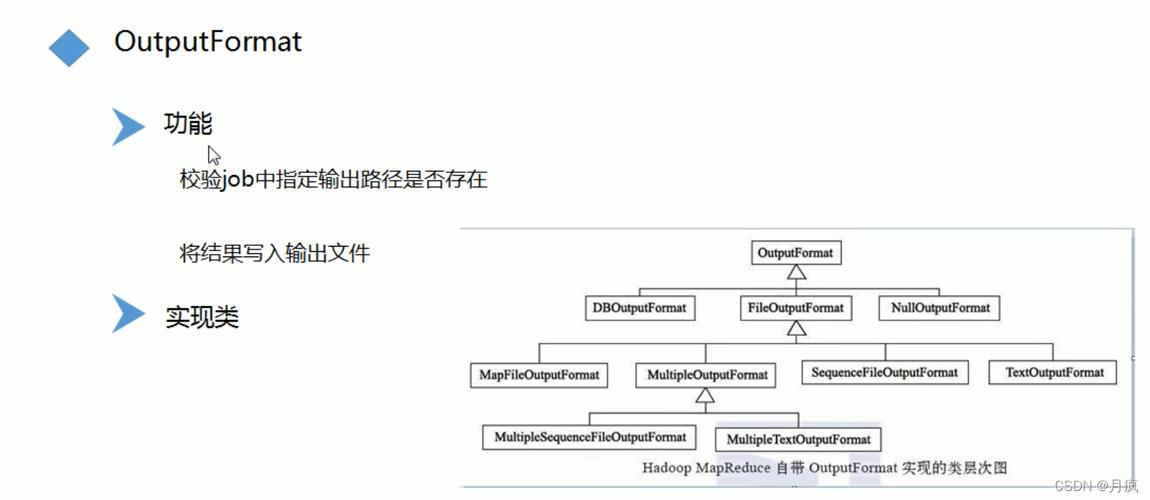
如何在MapReduce中实现自定义的数据输入和输出格式?
答: 可以通过实现Hadoop提供的InputFormat和OutputFormat接口来创建自定义的数据格式,这允许开发者控制如何读取输入数据以及如何写入输出数据。
(图片来源网络,侵删)
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/586068.html
 微信扫一扫
微信扫一扫