

hadoop jar命令后跟你的jar文件名。hadoop jar myMapReduce.jar com.example.MainClass input output,com.example.MainClass是你的主类,input和output`分别是输入和输出路径。如何使用MapReduce命令
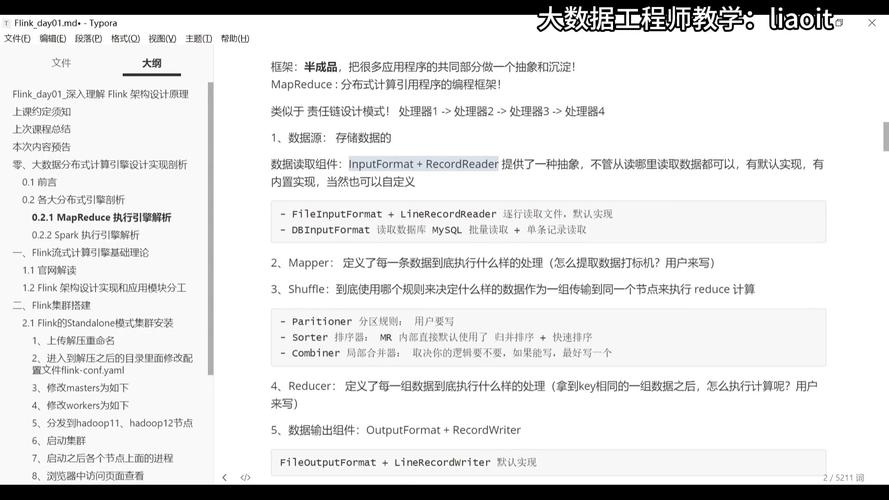

MapReduce是一种编程模型,用于处理和生成大数据集,它由两个主要步骤组成:Map(映射)和Reduce(归约),以下是使用MapReduce命令的基本步骤:
1、安装Hadoop: 你需要在你的计算机上安装Hadoop,你可以从官方网站下载并按照说明进行安装。
2、编写Map函数: Map函数负责处理输入数据并产生中间键值对,如果你想计算文本中每个单词的出现次数,你的Map函数可能会将每行文本拆分成单词,并为每个单词输出一个键值对,其中键是单词本身,值是1。
3、编写Reduce函数: Reduce函数接收所有具有相同键的中间键值对,并对它们进行处理以产生最终结果,在上面的例子中,Reduce函数会将所有相同的单词计数相加,得到每个单词的总出现次数。
4、配置Hadoop环境: 在运行MapReduce作业之前,你需要配置Hadoop环境,包括设置HDFS(Hadoop分布式文件系统)和YARN(Yet Another Resource Negotiator)。
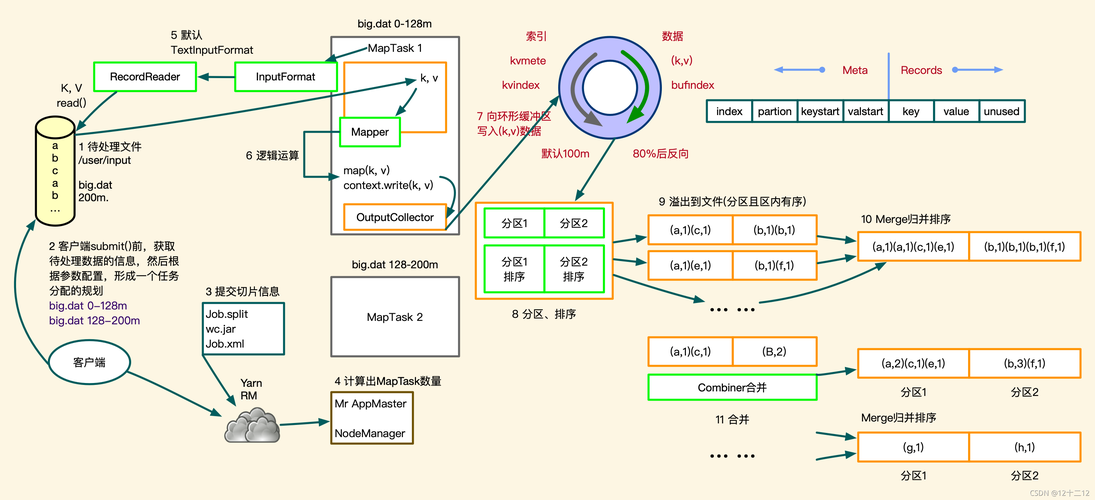
5、运行MapReduce作业: 使用以下命令来运行你的MapReduce作业:
```
hadoop jar <path_to_your_jar_file> <main_class> <input_path> <output_path>
```
<path_to_your_jar_file> 是你的MapReduce程序打包成的JAR文件的路径。
<main_class> 是你的MapReduce程序的主类名。
<input_path> 是HDFS上的输入数据的路径。
<output_path> 是在HDFS上存储输出结果的路径。
6、查看结果: 一旦作业完成,你可以使用以下命令查看输出结果:
```
hadoop fs cat <output_path>/
```
常见问题与解答
Q1:如何调试MapReduce作业?
A1: 调试MapReduce作业可以有多种方法,一种常见的方法是使用日志文件来查找错误信息,你可以在Hadoop配置文件中启用详细的日志记录,或者直接在命令行中使用verbose选项运行作业,你还可以使用Hadoop自带的Web界面来监控作业的状态和进度。
Q2:MapReduce作业的性能优化有哪些技巧?
A2: 优化MapReduce作业的性能可以从多个方面入手,确保你的Map和Reduce函数尽可能地高效,合理地调整分区数量和并行度可以提高任务执行的效率,选择合适的数据结构和算法也非常重要,还可以考虑使用压缩技术来减少数据传输量,以及利用本地化策略来减少网络开销。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/586116.html
 微信扫一扫
微信扫一扫