

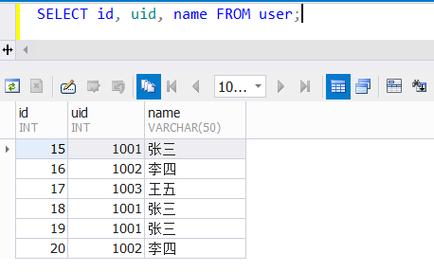
sql,SELECT 电话号码, COUNT(*) as 出现次数,FROM 来电表,GROUP BY 电话号码,HAVING 出现次数 > 1;,``在MySQL数据库应用中,识别并处理重复的记录是维护数据准确性与完整性的关键步骤之一,本文将深入探讨如何在MySQL中查询重复记录,特别是针对如“重复来电”这类实际场景的应用,通过使用GROUP BY和HAVING语句,可以轻松识别出存在重复值的记录,并通过一些额外的策略保留最关键的信息,例如最新时间的记录,小编将详细介绍这一过程:

1、基本查询策略
使用 GROUP BY 和 HAVING:一种常见的方法是组合使用GROUP BY和HAVING语句,若要查找所有出现次数超过一次的电子邮件地址,可以使用以下查询:
```sql
SELECT email, COUNT(email)
FROM users
GROUP BY email
HAVING COUNT(email) > 1;
```
这个查询会返回每个重复电子邮件地址及其出现的次数。
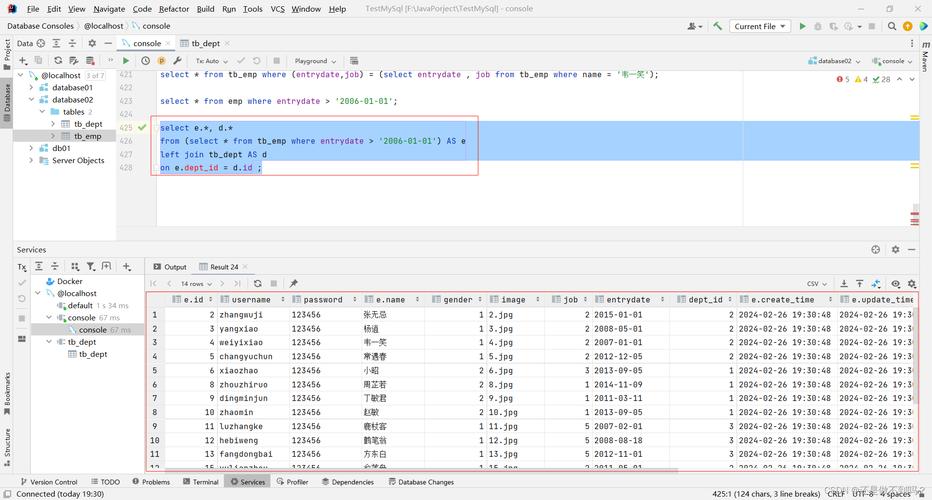
获取重复记录的详细信息:若需要获取每个重复记录的全部信息,可以采用子查询或JOIN操作,以下是一个使用子查询的例子:
```sql
SELECT
FROM users
WHERE email IN (
SELECT email
FROM users
GROUP BY email
HAVING COUNT(email) > 1
);
```
这个查询将返回所有列的信息对于电子邮件字段存在重复的记录。
2、保留时间最大的一条记录
复合查询策略:在实际应用中,如“重复来电”的场景,通常需要从重复记录中筛选出时间最新的一条进行保留,这可以通过创建一个复合查询实现,如下所示:
```sql
SELECT
FROM users AS outer_user
WHERE id = (
SELECT max(id) # 假设id与时间正相关
FROM users AS inner_user
WHERE inner_user.email = outer_user.email
GROUP BY inner_user.email
HAVING COUNT(inner_user.email) > 1
);
```
这个查询确保从每个重复的邮件组中选出时间上最新的一条记录(基于ID和时间正相关的假设)。
3、分析与优化
性能考量:在执行此类查询时,重要的是考虑到性能因素,尤其是当处理大量数据时,确保相关的列已经被索引可以显著提高查询效率。
数据更新策略:查询重复记录后,可能需要进一步的数据清理工作,如更新或删除重复项,这应根据具体的业务需求和规则谨慎进行。
通过使用MySQL中的GROUP BY和HAVING语句,可以有效地查询出数据库中的重复记录,通过合理的设计和查询优化,可以在保持数据整洁的同时,确保查询效率和数据的准确性。
相关问题与解答
Q1: 如何避免在未来插入数据时产生重复记录?
A1: 可以通过设置数据库表的相应字段为唯一键(UNIQUE)来避免未来插入重复数据,在应用程序层面加入检查机制,确保在尝试插入已存在的数据前进行验证。
Q2: 是否可以自动删除重复记录中的旧记录?
A2: 是的,可以通过创建触发器或使用事务来自动处理,可以在更新或插入操作的触发器中包含逻辑来删除或更新非最新的重复记录,确保数据的最新性和唯一性。
通过这些策略,可以高效地管理和查询MySQL中的重复记录,同时保证数据的完整性和准确性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/586312.html
 微信扫一扫
微信扫一扫