

MapReduce详解与应用实例
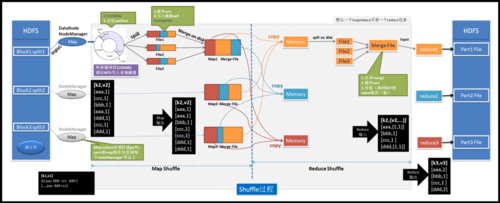

随着信息技术的飞速发展,大数据时代的到来使得数据处理的需求日益增加,MapReduce作为一种强大的分布式计算模型,广泛应用于海量数据的处理任务中。
MapReduce基础知识
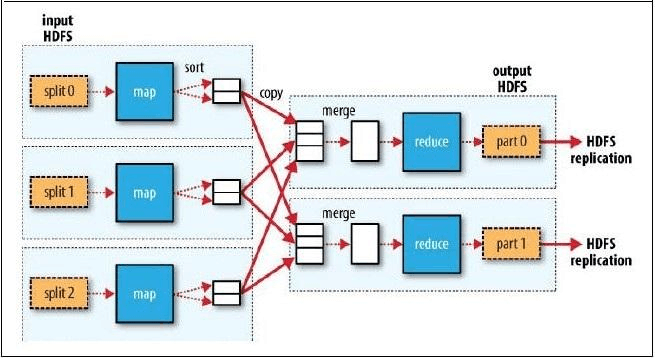
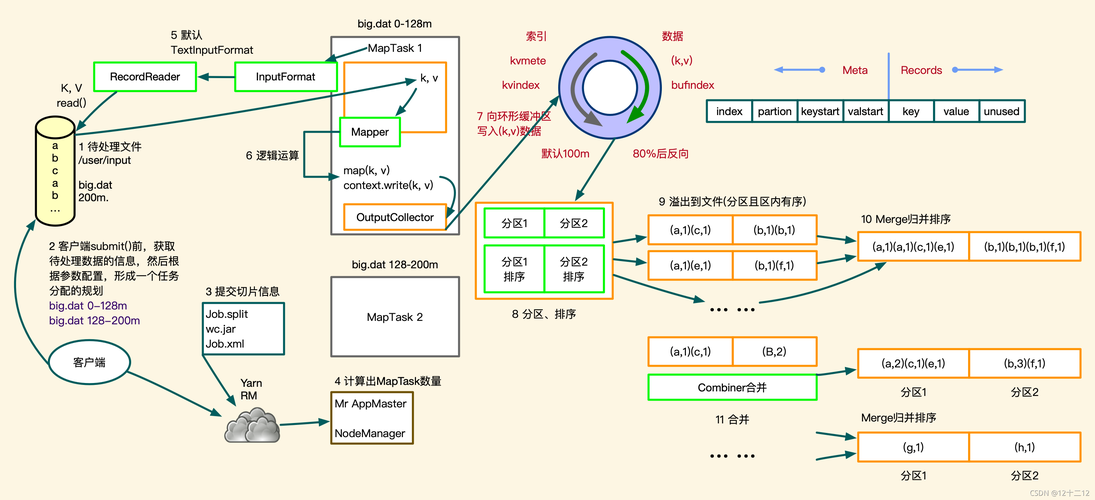
MapReduce是一个编程模型,它允许开发者编写出分布式的程序来处理大规模数据集,其核心包括两个阶段:Map阶段和Reduce阶段,在Map阶段,系统会将输入数据分成多块,并行处理;而在Reduce阶段,则会将Map阶段的输出整合起来,得到最终的结果。
详细操作实例
接下来通过几个典型的操作实例来进一步理解MapReduce的应用。
1. 排序
MapReduce框架会自动对键进行升序自然排序,给定文件file1和file2的内容,可以使用MapReduce来实现自定义排序规则。
2. 去重
在处理如好友关系数据时,经常会遇到重复记录的情况。"joe, jon"和"jon, joe"应被视为同一对好友关系,使用MapReduce可以高效地实现去重操作。
3. 求和与平均数
对于数值型数据,MapReduce可以方便地进行求和和平均数计算,这通常用于统计数据的总和或平均值。
4. TopK查询
MapReduce能够高效执行TopK查询,即查找排名前K位的记录,这对于热门商品的排名、热点话题分析等场景非常有用。
相关优缺点
MapReduce的优点在于其易于编程和良好的扩展性,用户只需要实现简单的接口即可完成复杂的数据分析任务,并且当计算资源不足时,可以通过增加机器来轻松扩展系统的计算能力。
相关问题与解答
Q1: MapReduce如何保证数据在分布式环境中的正确处理?
A1: MapReduce通过将大任务分解为多个小任务,并在多个节点上并行处理这些小任务来确保数据的处理效率和正确性,每个Map任务处理一部分数据,并生成中间结果,然后Reduce任务将这些中间结果合并成最终的输出。
Q2: 如何优化MapReduce作业的性能?
A2: 优化MapReduce作业性能的方法包括合理设置数据分区、调整Map和Reduce任务的数量、优化数据序列化方式以及合理配置Hadoop集群参数等。
通过上述实例和问题解答,希望读者能对MapReduce有更深入的理解和应用,MapReduce作为处理大数据的强有力工具,其在数据分析领域的应用前景广阔。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/586364.html
 微信扫一扫
微信扫一扫