

MapReduce是一种用于大规模数据处理的编程模型,由Google在2004年提出,并且在大数据技术领域迅速获得了广泛应用,小编将深入探讨MapReduce的组件、流程以及其实现代码的简要介绍,并通过相关问题与解答栏目对一些常见疑问进行阐释。

MapReduce
基本概念
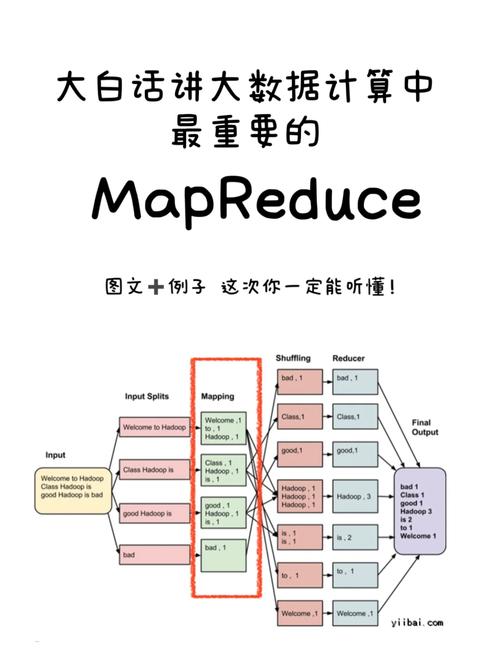
MapReduce的核心思想是将复杂的数据处理任务分解为两个阶段:Map阶段和Reduce阶段,在Map阶段,数据被分割成多个小块,每一块都由一个Mapper处理;Reduce阶段则负责将Map阶段的输出整合得到最终结果。
发展历程
2003年:Google发表了《The Google File System》,为处理大规模数据提供了存储方案。
2004年:Google推出了MapReduce模型,简化了大集群上的数据处理流程。
2006年:Google发表了《Bigtable: A Distributed Storage System for Structured Data》,进一步丰富了大数据生态系统。
核心优点
1、易于编程:开发者仅需实现Map和Reduce两个函数就能完成分布式程序的设计。
2、扩展性良好:可以通过增加计算资源来轻松扩展系统的计算能力。
MapReduce 组件与流程
Map组件
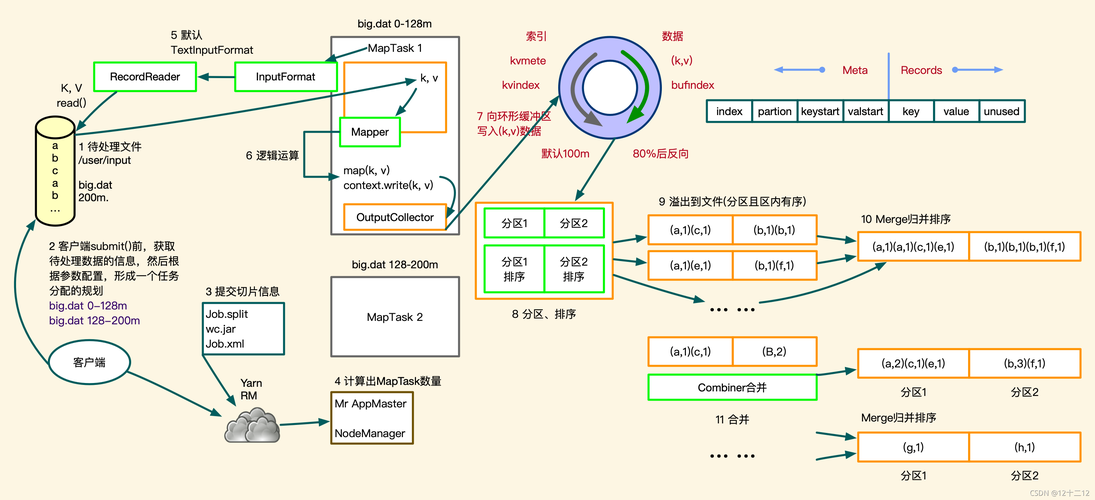
1、数据分片: 输入数据集划分为多个数据块。
2、映射函数应用: 每个Mapper对其分配的数据块应用映射函数。
3、中间键值对生成: 映射函数输出零个或多个中间键值对。
Reduce组件
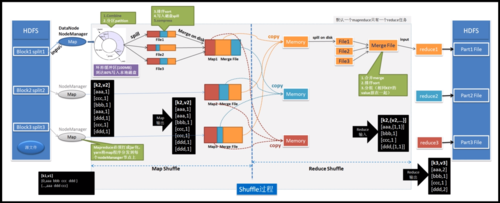
1、Shuffle: Map阶段的输出按照key值进行聚集。
2、Reduce: 对每一个唯一的key值执行用户定义的Reduce函数,整合结果。
流程归纳
1、读取输入数据并分片。
2、各个Mapper并行处理数据块。
3、Mapper输出中间键值对。
4、Shuffle过程按key聚集数据。
5、Reducer处理聚集后的数据,输出最终结果。
代码实现简介
Map函数
接收输入的key/value对。
产生一系列中间key/value对。
Reduce函数
接受一个key及对应的value列表作为输入。
对列表中的values进行处理,输出结果。
相关问题与解答
Q1: MapReduce适用于哪些场景?
A1: MapReduce特别适用于需要处理大量非结构化或半结构化数据的批处理任务,如日志分析、数据挖掘等。
Q2: MapReduce存在哪些局限性?
A2: MapReduce的主要局限性在于其不适合于需要低延迟响应的实时计算任务,且对于具有复杂依赖关系的任务来说,编写高效的MapReduce作业较为困难。
MapReduce通过其简洁而强大的模型,极大地促进了大数据处理技术的发展,尽管存在一定的局限性,但其在数据处理领域的地位仍然不可动摇,了解其工作原理和适用场景,对于从事相关领域的专业人员而言,是一项必备的技能。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/586856.html
 微信扫一扫
微信扫一扫