

MapReduce Job 配置基线
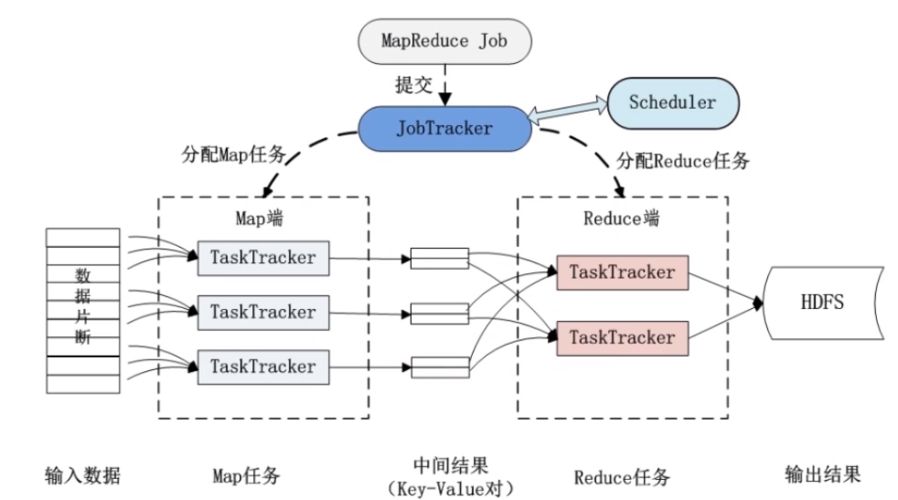

MapReduce作业是Hadoop框架中用于处理大规模数据集的一种编程模型,它包括两个主要阶段:Map和Reduce,每个阶段都由多个任务(Task)组成,正确配置MapReduce作业对于确保性能和可靠性至关重要,以下是配置MapReduce作业的基线指南。
1. Job配置
1.1 设置Job名称
为每个Job指定一个有意义的名称,以便在监控和日志中轻松识别。
job.setJobName("My MapReduce Job");
1.2 配置输入和输出路径
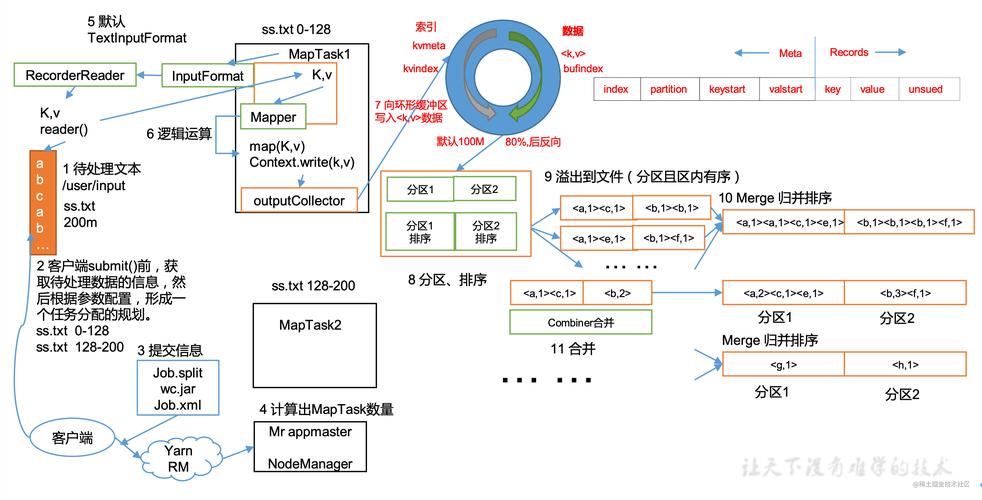
指定作业的输入和输出HDFS路径。
FileInputFormat.addInputPath(job, new Path(inputPath)); FileOutputFormat.setOutputPath(job, new Path(outputPath));
1.3 设置Mapper和Reducer类
定义作业使用的Mapper和Reducer类。
job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class);
1.4 设置Map和Reduce的数量
根据集群大小和作业需求调整Map和Reduce任务的数量。
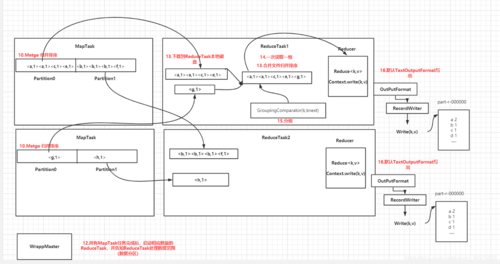
job.setNumReduceTasks(numReduceTasks);
1.5 配置输出键值类型
指定Mapper输出和最终输出的键值对类型。
job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class);
2. 高级配置
2.1 压缩
启用中间数据和输出数据的压缩以节省存储空间和网络带宽。
job.setMapOutputCompressorClass(CompressionCodec.class); FileOutputFormat.setCompressOutput(job, true);
2.2 自定义排序
如果需要,可以实现自定义排序来优化Reduce阶段的处理。
job.setSortComparatorClass(MyComparator.class);
2.3 跳过坏记录
配置作业以跳过处理过程中的错误记录,避免整个作业失败。
LazyOutputFormat.setOutputFormatClass(job, TextOutputFormat.class);
3. 性能调优
3.1 合理设置内存
根据任务需求调整JVM堆大小和其他内存参数。
mapreduce.map.memory.mb=1024 mapreduce.reduce.memory.mb=2048
3.2 启用推测执行
开启推测执行可以在慢任务上启动备份任务,以减少整体作业时间。
mapreduce.map.speculative=true mapreduce.reduce.speculative=true
3.3 调整I/O缓冲区大小
增加I/O缓冲区大小可以提高数据处理速度。
io.sort.mb=200
相关问题与解答
Q1: MapReduce作业中的推测执行是什么?
A1: 推测执行是Hadoop中的一个特性,它允许系统为长时间运行的任务启动一个备份任务,如果原始任务完成,备份任务将被终止,其目的是减少作业的总运行时间。
Q2: 如何控制MapReduce作业的内存使用?
A2: 可以通过在mapredsite.xml或作业配置中设置mapreduce.map.memory.mb和mapreduce.reduce.memory.mb参数来控制Map和Reduce任务的内存使用,还可以通过设置mapreduce.map.java.opts和mapreduce.reduce.java.opts来调整JVM的启动参数。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/587219.html
 微信扫一扫
微信扫一扫