

在当前的数字时代,社交网络平台面临着连接人们、增强互动的挑战,好友推荐系统是解决这一挑战的关键功能之一,通过使用MapReduce模型,能够高效处理大量数据并实现复杂的推荐算法,将详细探讨如何利用MapReduce实现好友推荐系统:

一、需求分析与基本思路
1、核心目标
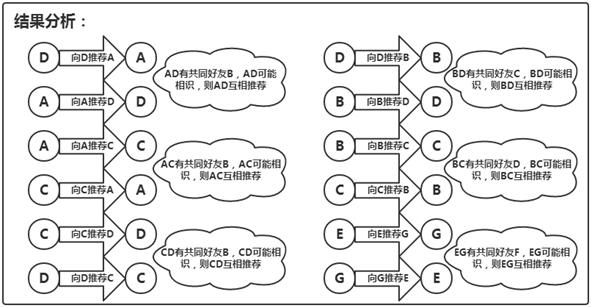
推荐逻辑:用户之间若有共同好友,则可以进行相互推荐,共同好友数量越多,推荐的优先级越高。
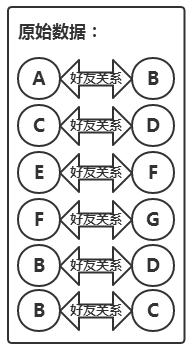
数据准备:需要准备包含用户间好友关系的数据集,这些数据可以是直接从社交平台获取的用户关系图。
2、关键问题

如何定义Key:合理定义Key是MapReduce成功实现的关键,在此场景中,可以将用户对(如AB)作为Key,这样在Reduce阶段可以汇总每个用户对的共同好友数。
区分直接与间接好友关系:直接好友不需要推荐,间接好友则需要,这需要在Map阶段进行标记和区分。
二、MapReduce实现步骤
1、环境准备
硬件与软件配置:确保Hadoop和Zookeeper集群已在多台虚拟机上搭建完成,HDFS和MapReduce环境配置正确。
数据存储:确定数据存储位置,如HDFS上的特定路径/mrxx。
2、具体实现
Map阶段任务:生成用户间的关系,包括直接好友和间接好友的标记,同时对用户ID进行排序以保证AB与BA为同一关系。
Reduce阶段任务:根据Map输出的关系,计算每对用户间的共同好友数,并进行推荐值的计算。
三、关键技术点
1、数据的准备与输入
生成测试数据:可以通过工具类随机生成好友关系作为测试数据。
格式与结构:确保数据的格式适合MapReduce处理,如使用文本文件,每行一个用户对。
2、算法设计
共同好友数的统计:在Reduce阶段,对所有传入的用户对进行遍历,统计共同好友的数量。
推荐逻辑的应用:根据统计结果应用推荐逻辑,如设定阈值决定是否进行推荐。
四、案例与代码实现
1、实际案例
FriendsRecommend项目:一个具体的Hadoop MapReduce项目,用于计算和排序根据共同好友数量得出的推荐值。
MyFoF类:定义了配置和执行map及reduce程序所需的类。
2、代码实例
Mapper类实现:重写Mapper类,用于处理原始数据,生成用户对及其关系。
Reducer类实现:重写Reducer类,用于处理Mapper输出的数据,实现统计和推荐逻辑。
五、优化与进阶
1、性能优化
合理设置Reduce任务数量:根据数据集的大小和复杂度调整Reduce任务的数量,以优化性能。
数据预处理:在输入MapReduce之前,对原始数据进行预处理,如去除噪声和不相关的数据。
2、功能拓展
引入更多维度:除共同好友数外,可以考虑其他推荐指标,如用户活跃度、兴趣相似度等。
实时推荐系统:考虑使用Spark等技术实现实时数据处理和推荐,提高系统的响应速度和用户体验。
六、常见问题解答
1、问:如何处理新用户没有好友的情况?
答:对于新用户没有好友的情况,可以通过推荐系统中的其他指标,如兴趣相似度、活动参与度等进行推荐,可以引导新用户通过非好友推荐的方式发现内容或参与活动。
2、问:如何评估好友推荐系统的效果?
答:可以通过几种方式来评估好友推荐系统的效果:一是观察用户的互动率,即推荐后用户之间形成新的好友关系的比例;二是通过用户满意度调查获取反馈;三是利用A/B测试对比不同推荐策略的效果。
利用MapReduce实现好友推荐系统不仅可行,而且能够高效地处理大规模数据集,通过上述的需求分析、实现步骤、关键技术点、案例与代码实现以及优化与进阶,可以构建出既准确又高效的推荐系统,随着技术的不断进步和用户需求的变化,持续优化和更新推荐算法将是提高用户满意度和互动率的关键。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/587430.html
 微信扫一扫
微信扫一扫